Web applications handle data much differently than they did ten years ago. They’re gathering more information, and more users are accessing it simultaneously, posing a challenge for traditional, schema-based relational databases that struggle to scale.
The Rise of NoSQL
Recognizing the limitations of SQL scalability, Web 2.0 giants like Google, Amazon, and Facebook devised their own solutions, giving rise to technologies like BigTable, DynamoDB, and Cassandra.
This spurred the development of various NoSQL Database Management Systems (DBMS) prioritizing performance, reliability, and consistency. Existing indexing structures were refined to enhance search and read speeds.
Initially, large companies developed proprietary (closed-source) NoSQL databases to meet their unique requirements, such as Google’s BigTable, considered the first NoSQL system, and Amazon’s DynamoDB.
The success of these proprietary systems paved the way for numerous open-source and proprietary alternatives, with Hypertable, Cassandra, MongoDB, DynamoDB, HBase, and Redis emerging as front-runners.
What Makes NoSQL Different?
A key distinction between NoSQL and traditional relational databases lies in NoSQL’s unstructured storage.
Unlike their relational counterparts, NoSQL databases lack a fixed table structure.
Advantages and Disadvantages of NoSQL Databases
Advantages
NoSQL databases offer several advantages over traditional databases.
Their simple, flexible, and schema-free structure is a fundamental difference.
Instead of tables, NoSQL databases rely on key-value pairs.
Various NoSQL data store types exist, including column store, document store, key value store, graph store, object store, XML store, and more.
Typically, each database value has a corresponding key. Some NoSQL databases even allow developers to store serialized objects beyond simple strings.
Open-source NoSQL databases eliminate expensive licensing fees and run on affordable hardware, making them cost-effective to deploy.
Expansion is also simpler and more economical with NoSQL databases, whether open-source or proprietary. Horizontal scaling distributes the load across nodes, unlike the vertical scaling typical of relational databases, which involves replacing the main host with a more powerful one.
Disadvantages
NoSQL databases are not without their limitations and are not always the ideal solution.
One drawback is that most lack the reliability features inherent in relational database systems, such as atomicity, consistency, isolation, and durability. This means that NoSQL databases often prioritize performance and scalability over consistency.
To ensure reliability and consistency, developers must implement custom code, increasing system complexity.
This may restrict the use of NoSQL databases in applications requiring secure and reliable transactions, such as banking systems.
Other complexities include incompatibility with SQL queries, necessitating manual or proprietary querying languages, which adds time and complexity.
NoSQL vs. Relational Databases
This table provides a concise feature comparison between NoSQL and relational databases:
| Feature | NoSQL Databases | Relational Databases |
|---|---|---|
| Performance | High | Low |
| Reliability | Poor | Good |
| Availability | Good | Good |
| Consistency | Poor | Good |
| Data Storage | Optimized for huge data | Medium sized to large |
| Scalability | High | High (but more expensive) |
Importantly, this comparison focuses on the database level, not the specific database management systems implementing each model. These systems often incorporate proprietary techniques to address limitations and enhance performance and reliability.
NoSQL Data Store Types
Key Value Store
Key Value stores utilize a hash table where unique keys point to specific items.
Keys can be organized into logical groups, with uniqueness required only within the group, allowing identical keys in different logical groups.
| Key | Value |
|---|---|
| "Belfast" | {“University of Ulster, Belfast campus, York Street, Belfast, BT15 1ED”} |
| “Coleraine" | {“University of Ulster, Coleraine campus, Cromore Road, Co. Londonderry, BT52 1SA”} |
Some key-value stores implement caching mechanisms for significant performance improvements.
Accessing stored items requires only the key. Data is stored as strings, JSON, or BLOBs (Binary Large Objects).
A significant drawback of this database type is the lack of database-level consistency. While developers can address this with custom code, it increases effort, complexity, and time.
Amazon’s DynamoDB is a prominent example of a key-value store NoSQL database.
Document Store
Document stores resemble key-value stores in their schema-less nature and key-value model, sharing many advantages and disadvantages. Both lack inherent database-level consistency, requiring applications to implement reliability and consistency features.
However, key differences exist.
Document stores encode stored data (documents) in formats like XML, JSON, or BSON (Binary encoded JSON).
Querying based on data content is also possible.
MongoDB is a widely used database application based on a Document Store.
Column Store
Column store databases organize data into columns rather than rows, unlike most relational database management systems.
They consist of one or more Column Families logically grouping specific database columns. A key identifies and points to multiple columns, with a keyspace attribute defining the key’s scope. Each column contains comma-separated tuples of names and values.
Column stores excel at fast read/write access. Rows corresponding to a single column are stored as a single disk entry, accelerating read/write operations.
Popular column store databases include Google’s BigTable, HBase, and Cassandra.
Graph Base
Graph base NoSQL databases represent data using a directed graph structure composed of edges and nodes.
Formally, a graph represents a set of objects with links connecting some pairs. Interconnected objects are represented as vertices, and the links are edges. The vertices and connecting edges constitute the graph.
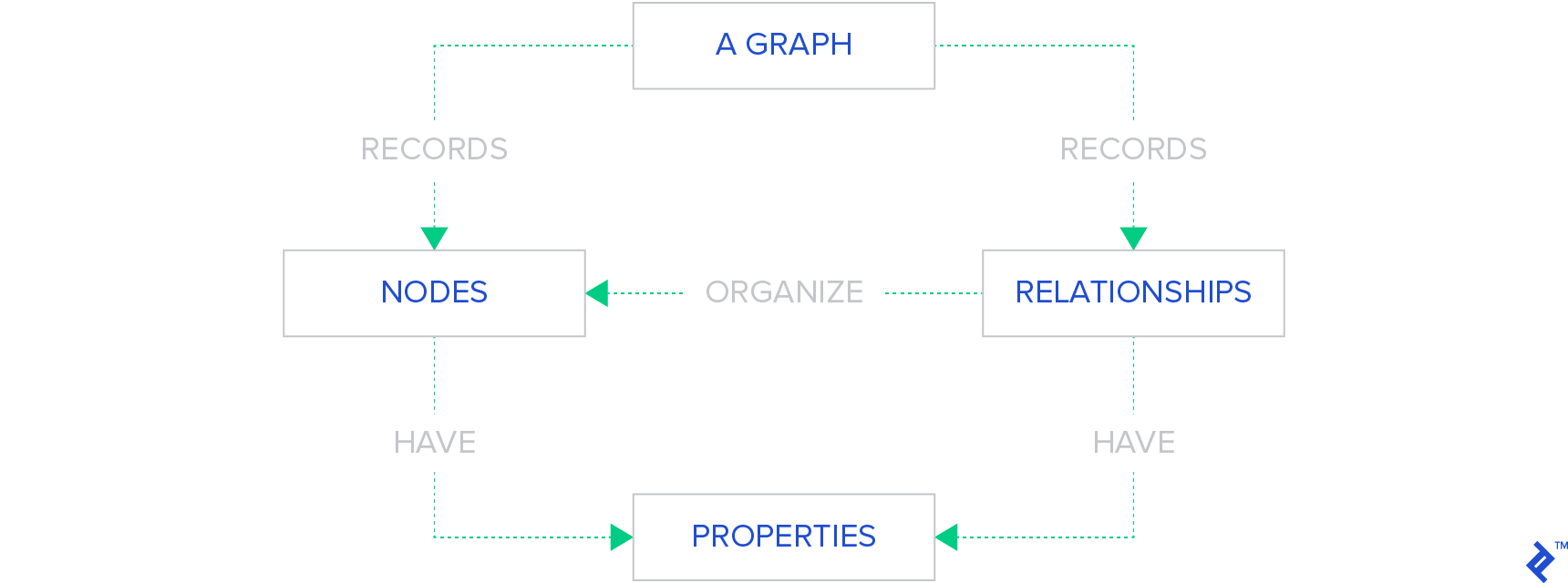
This illustrates the structure of a graph base database, where nodes represent and store data, and edges depict relationships between them. Both nodes and relationships have defined properties.
Graph databases are commonly employed in social networking applications. They allow developers to prioritize relationships between objects rather than the objects themselves, providing a scalable and user-friendly environment.
Currently, InfoGrid and InfiniteGraph are popular graph database options.
NoSQL Database Management Systems
This table offers a concise comparison of different NoSQL database management systems:
| Storage Type | Query Method | Interface | Programming Language | Open Source | Replication | |
|---|---|---|---|---|---|---|
| Cassandra | Column Store | Thrift API | Thrift | Java | Yes | Async |
| MongoDB | Document Store | Mongo Query | TCP/IP | C++ | Yes | Async |
| HyperTable | Column Store | HQL | Thrift | Java | Yes | Async |
| CouchDB | Document Store | MapReduce | REST | Erlang | Yes | Async |
| BigTable | Column Store | MapReduce | TCP/IP | C++ | No | Async |
| HBase | Column Store | MapReduce | REST | Java | Yes | Async |
MongoDB features flexible schema storage, meaning stored objects don’t require identical structures or fields. Its optimization features distribute data collections for enhanced performance and system balance.
Other NoSQL databases, like Apache CouchDB, also employ a document store model, sharing many features with MongoDB but offering access through RESTful APIs.
REST, an architectural style for web services, enforces constraints on components, connectors, and data elements. It relies on a stateless, client-server, cacheable communication protocol like HTTP.
RESTful applications use HTTP requests to manage data (post, read, and delete).
Hypertable, a column-based NoSQL database written in C++, is inspired by Google’s BigTable.
Like MongoDB and CouchDB, Hypertable supports distributed data stores across nodes for maximum scalability.
Cassandra, developed by Facebook, is a widely used column store database.
It boasts numerous features designed for reliability and fault tolerance.
While primarily a column store, Cassandra draws inspiration from Google’s BigTable (column store) and Amazon’s DynamoDB (key-value) to offer a hybrid approach.
It provides a key-value system where keys point to sets of column families, leveraging Google’s BigTable distributed file system and Dynamo’s availability features (distributed hash table).
Cassandra excels at handling vast amounts of data across multiple servers, ensuring high availability and eliminating single points of failure, crucial for services like Facebook.
Key features of Cassandra include:
- No single point of failure: Cassandra runs on a cluster of nodes, not a single machine, to achieve this. While data may not be identical across all nodes, management software is. If one node fails, its data becomes inaccessible, but other nodes and their data remain available.
- Distributed Hashing: This scheme distributes hash table functionality, so adding or removing a slot minimally impacts key-to-slot mapping. This enables load distribution based on server capacity, minimizing downtime.
- User-friendly Client Interface: Cassandra utilizes Apache Thrift, offering a cross-language RPC client, though many developers favor open-source alternatives built on Thrift, such as Hector.
- Additional Availability Features: Data replication mirrors data to other cluster nodes, randomly or strategically, for data protection (e.g., placing replicas in different data centers). The partitioning policy determines key placement on nodes, randomly or in order. By combining these policies, Cassandra balances load balancing and query performance optimization.
- Consistency: Features like replication pose consistency challenges, as all nodes must remain up-to-date with the latest values, especially during read operations. However, Cassandra strives for a balance between replication and read/write actions by offering developer customization.
- Read/Write Actions: Clients send requests to a single Cassandra node. Based on the replication policy, the node stores data across the cluster. Each node first synchronously logs the data change in the commit log and then updates the table structure. Read operations function similarly: a request is sent to a node, which determines the data’s location based on the partitioning/placement policy.
MongoDB
MongoDB, a schema-free, document-oriented database written in C++, utilizes a document store model, storing values (documents) as encoded data.
The chosen encoding format is JSON, enabling querying and indexing even within nested data.
Let’s explore some key features of MongoDB:
Shards
Sharding involves partitioning and distributing data across multiple machines (nodes). In contrast to Cassandra’s symmetrical node distribution, a shard in MongoDB represents a collection of nodes. Sharding facilitates horizontal scalability. Applications using a single database server can transition to a sharded cluster with minimal code modifications due to MongoDB’s decoupling of sharding from public client-side APIs.
Mongo Query Language
MongoDB leverages a RESTful API. To retrieve specific documents from a collection, a query document specifies the fields that desired documents should match.
Actions
MongoDB utilizes router servers, each handling one or more clients. Configuration servers within the cluster maintain metadata indicating data distribution across shards. Client read/write actions are sent to a router server, which, guided by configuration servers, routes them to the appropriate shards containing the data.
Like Cassandra, MongoDB shards employ data replication, creating replica sets with identical data. Two replication schemes exist: Master-Slave and Replica-Set. Replica-Set offers greater automation and failure handling, while Master-Slave may require administrator intervention. Regardless of the scheme, only one shard within a replica set acts as the primary shard for all write and read operations, which are then distributed to secondary shards if needed.
The graphic below illustrates the MongoDB architecture, with router servers in green, configuration servers in blue, and shards containing MongoDB nodes:
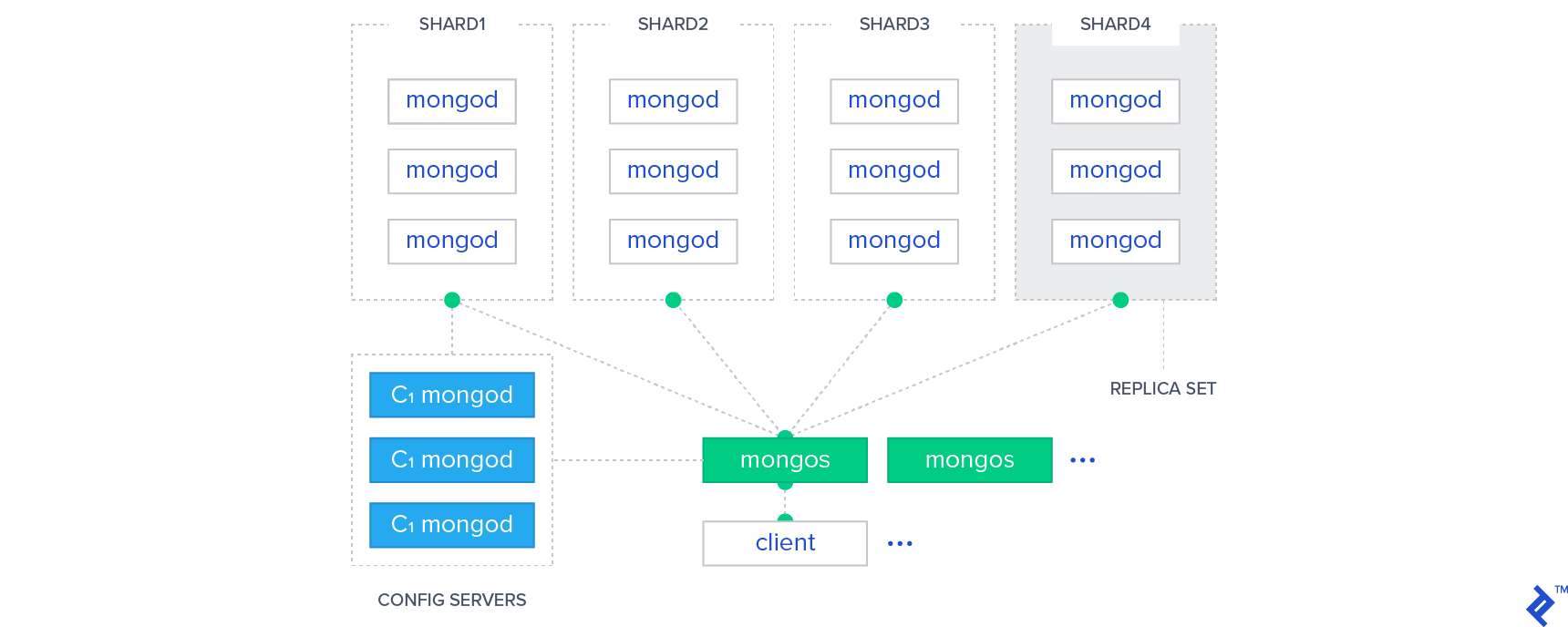
MongoDB’s automatic sharding contributes to its high scalability and reduced failure rate.
Indexing Structures for NoSQL Databases
Indexing links a key to the location of its corresponding data record within a DBMS. NoSQL databases use various indexing structures. We’ll briefly examine some common methods: B-Tree, T-Tree, and O2-Tree indexing.
B-Tree Indexing
B-Tree is a widely used index structure in DBMSs.
Internal nodes in B-trees can have a variable number of child nodes within a predefined range.
Unlike AVL trees, B-Trees permit variable child nodes per node, leading to less balancing but potentially more wasted space.
The B+-Tree, a popular B-Tree variant, requires all keys to reside in the leaves.
T-Tree Indexing
T-Trees combine elements of AVL-Trees (self-balancing binary search trees) and B-Trees (unbalanced, with variable child nodes per node).
The T-Tree structure resembles both AVL and B-Trees.
Each node stores multiple {key-value, pointer} tuples. Binary search and multiple-tuple nodes enhance storage and performance.
T-Trees have three node types: T-Nodes (with left and right children), leaf nodes (no children), and half-leaf nodes (one child).
T-Trees are believed to outperform AVL-Trees overall.
O2-Tree Indexing
The O2-Tree improves upon Red-Black trees, a type of Binary-Search tree where leaf nodes hold {key value, pointer} tuples.
Designed for enhanced indexing performance, an O2-Tree of order m (m ≥ 2), where m represents the minimum degree, adheres to these properties:
- Nodes are either red or black, with a black root.
- Black leaf nodes consist of a block or page containing “key-value, record-pointer” pairs.
- Red nodes have black children.
- Internal nodes have equal black nodes on all paths to descendant leaf-nodes. Each internal node holds a single key value.
- Leaf-nodes (blocks) contain between ⌈m/2⌉ and m “key-value, record-pointer” pairs.
- Single-node trees are leaf nodes, serving as the root, and can have 1 to m key data items.
- Leaf nodes are doubly linked (forward and backward).
This table compares the performance of O2-Tree, T-Tree, B+-Tree, AVL-Tree, and Red-Black Tree:
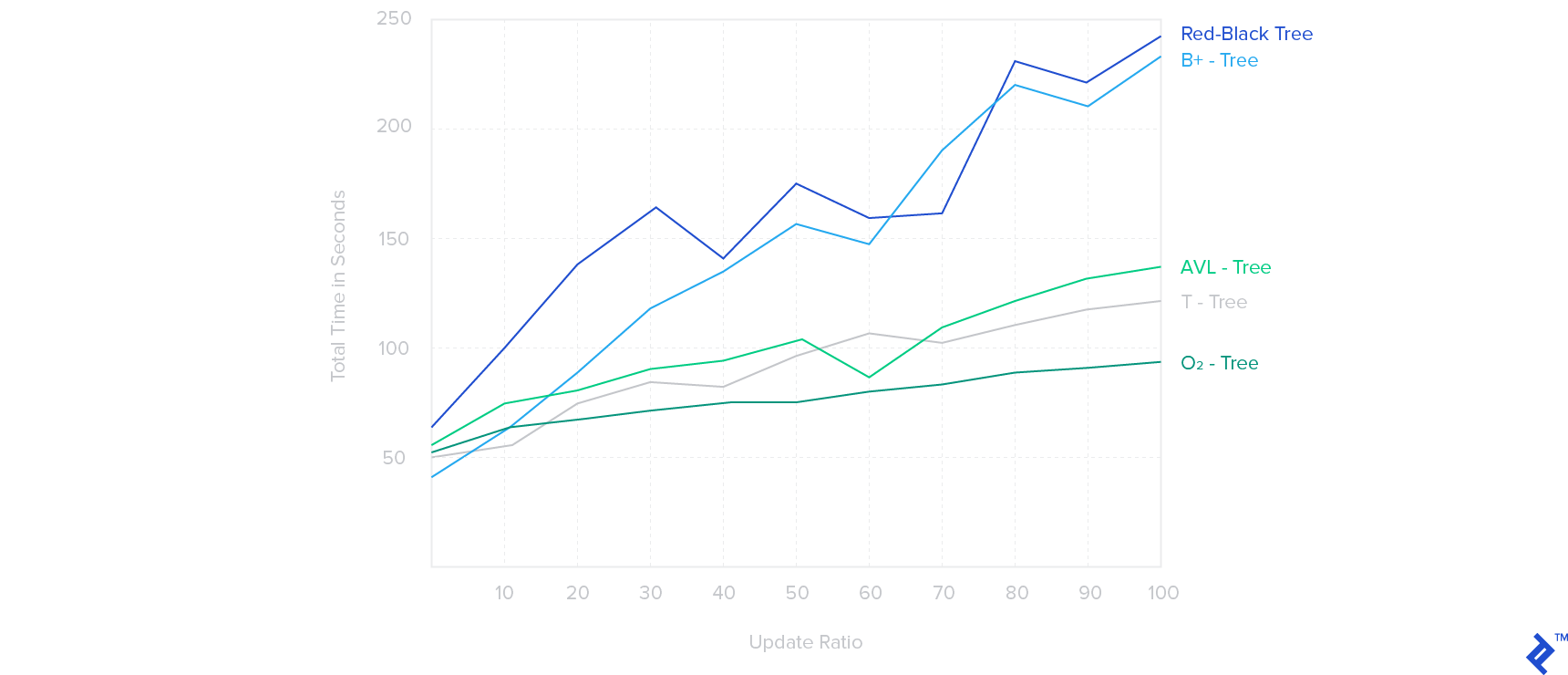
The tests used T-Tree, B+-Tree, and O2-Tree of order m = 512.
Time is measured for search, insert, and delete operations with varying update ratios (0%-100%) on a 50M record index, adding another 50M records.
B-Tree and T-Tree outperform O2-Tree with low update ratios (0-10%). However, as update ratios increase, O2-Tree demonstrates superior performance, while B-Tree and Red-Black Tree structures struggle the most.
The Case for NoSQL?
In conclusion, here’s what we’ve learned about NoSQL databases and where traditional relational databases fall short:
Relational databases offer consistency but are not ideal for high-performance applications handling massive, frequently accessed data.
NoSQL databases gained traction due to their high performance, scalability, and accessibility. However, they often lack features for robust consistency and reliability.
Fortunately, many NoSQL DBMSs are addressing these concerns with new features.
Performance comparisons are not always straightforward:
Not all NoSQL systems outperform relational databases.
MongoDB and Cassandra demonstrate comparable or better performance than relational databases in write and delete operations.
No direct correlation exists between store type and NoSQL DBMS performance.
NoSQL implementations constantly evolve, impacting performance.
Therefore, cross-database performance benchmarks should be treated cautiously and updated with the latest software versions.
Here are some takeaways on performance:
Traditional B-Tree and T-Tree indexing are common in traditional databases.
The O2-Tree combines features from multiple indexing structures, offering potential improvements.
O2-Tree outperformed other structures in most tests, particularly with large datasets and high update ratios.
B-Tree exhibited the poorest performance among the discussed indexing structures.
Future research should focus on enhancing the consistency of NoSQL DBMSs and exploring the integration of NoSQL and relational databases.
NoSQL complements existing database standards but comes with trade-offs. Prioritizing performance and scalability often means sacrificing reliability and consistency, making it a specialized solution.
However, when speed and efficiency are paramount, NoSQL is the tool for the job.