There are two main challenges in developing deep learning natural language processing (NLP) models for classification.
- Gathering data (acquiring thousands or millions of categorized data points)
- Designing and training deep learning architectures
Building sophisticated deep learning models that can comprehend the intricacies of language has historically necessitated years of expertise in these areas. The complexity of your problem, the diversity of your desired output, and the time required for each of these stages are all directly proportional.
Data collection is a demanding task that can be time-consuming, costly, and often poses the biggest obstacle to the success of NLP initiatives. Even with skilled machine learning engineers, preparing data, constructing reliable pipelines, choosing from countless potential preparation techniques, and making data “model-ready” can take months. Additionally, training and refining deep learning models require a blend of intuition, technical skill, and perseverance.
This article will delve into the following:
- Trends in deep learning for NLP: How transfer learning is democratizing access to world-class models
- Introducing BERT: An overview of Bidirectional Encoder Representations from Transformers (BERT), a powerful NLP solution
- How BERT functions and its potential to revolutionize how businesses approach NLP projects
Trends in Deep Learning
Naturally, improving accuracy was the initial focus in optimizing this process. LSTM (long-short term memory) networks brought about a revolution in many NLP tasks, but they demanded (and still do) a huge amount of data. Optimizing and training such models can consume days or even weeks on expensive, high-performance machines. Moreover, deploying these large models in production environments is costly and challenging.
The field of computer vision has long embraced transfer learning as a means to mitigate these complexity-inducing factors. Transfer learning enables the utilization of a model trained on a different yet related task to expedite the development of a solution for a new task. Retraining a model that can already identify trees requires far less effort than training a new model from scratch to distinguish bushes.
Consider this: if someone had never encountered a bush but had seen numerous trees throughout their life, explaining what a bush looks like would be considerably easier by relating it to their existing knowledge of trees rather than describing it from the ground up. Transfer learning mirrors this innate human learning process, making it a logical approach for deep learning tasks.
BERT reduces data requirements, training time, and ultimately delivers greater business value. It has made it possible for any company to develop NLP products of exceptional quality.
Enter BERT
BERT leverages “transformers” and is designed to generate sentence encodings. In essence, BERT is a language model built upon a specific deep learning architecture. Its primary function is to provide a contextual, numerical representation of a single sentence or a sequence of sentences. This digital representation then serves as input for a simpler, less intricate model. Notably, the results achieved are generally superior and necessitate a fraction of the input data for previously unsolved tasks.
Imagine being able to gather data in a day instead of a year and develop models using datasets that would have been insufficient for creating an LSTM model. The number of NLP tasks that become feasible for businesses that previously couldn’t afford the required development time and expertise is astounding.
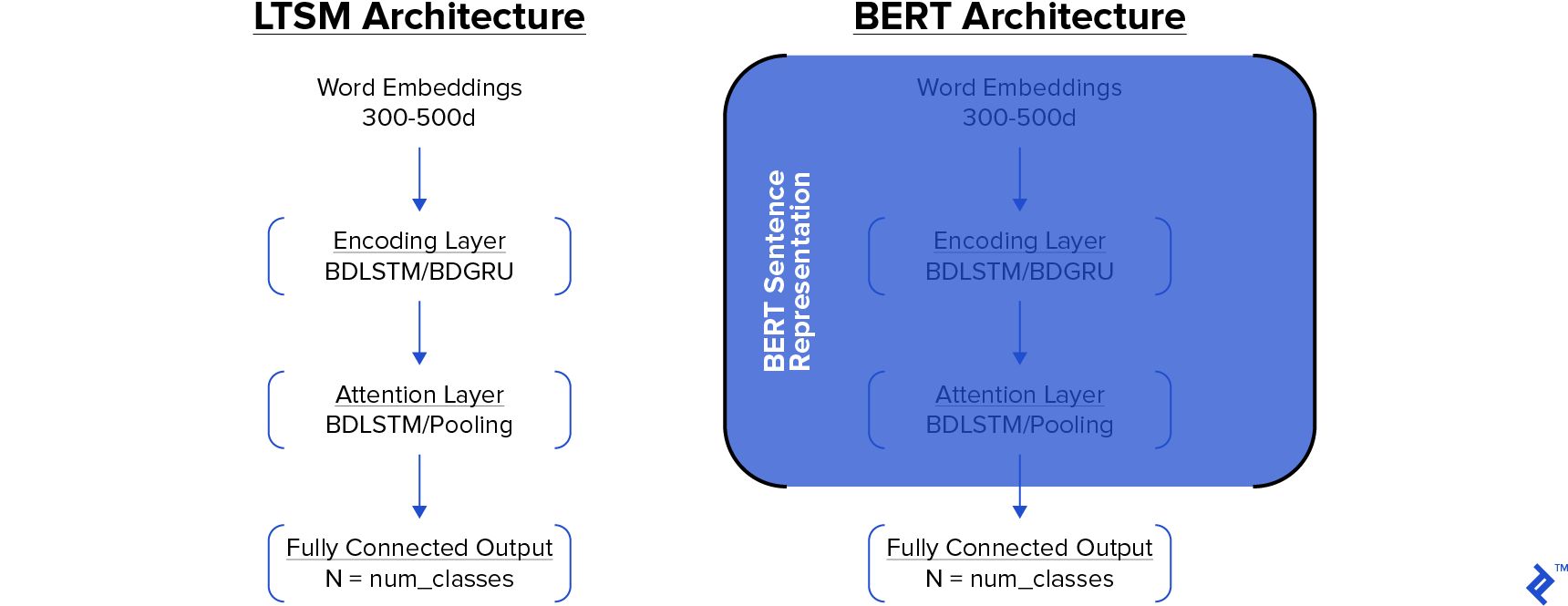
How BERT Works
In traditional NLP, the foundation of model training lies in word vectors. Word vectors are numerical sequences [0.55, 0.24, 0.90, …] that strive to quantitatively represent a word’s meaning. These numerical representations allow us to utilize words in training complex models. With extensive word vectors, we can embed significant information about words into these models.
BERT follows a similar principle (in fact, it also starts with word vectors), but instead of individual words, it generates a numerical representation of an entire input sentence (or multiple sentences).
BERT diverges from LSTM models in several key ways.
- It processes all words concurrently, as opposed to sequentially from left to right or right to left.
- During training, 15% of the words are randomly chosen to be “masked” (replaced with the [MASK] token).
- 10% of these randomly selected words are left unchanged.
- 10% of the masked words are replaced with randomly chosen words.
- Steps (a) and (b) work in tandem to compel the model to predict every word in the sentence (models tend towards efficiency).
- BERT then aims to predict all the words in the sentence, with only the masked words (including unchanged and randomly replaced ones) contributing to the loss function.
- The model is fine-tuned using “next sentence prediction,” where it tries to determine if a given sentence logically follows the preceding one in the text.
While convergence may be gradual and BERT’s training time-consuming, it demonstrates a superior ability to grasp the contextual relationships within text. Word vectors, due to their shallow representation, have limited modeling capabilities, a constraint that BERT overcomes.
Previously, many businesses leveraged pre-trained LSTM models that utilized multiple GPUs and demanded days of training for their specific applications. However, BERT enables teams to accelerate solution development tenfold compared to these older models. It allows for a rapid transition from identifying a business need to building a proof of concept and subsequently deploying that concept into production. That being said, there are instances where existing BERT models can’t be directly applied or fine-tuned for a specific use case.
Implementing BERT and Assessing Business Value
To illustrate the practical applications and engineering aspects of building a real-world product, we’ll create and train two models for a comparative analysis.
- BERT: A straightforward BERT pipeline where text undergoes standard processing, BERT sentence encodings are generated, and these encodings are fed into a shallow neural network.
- LSTM: The conventional Embed - Encode - Attend - Predict architecture (as depicted previously).
The task at hand? Predicting the country of origin for movies based on their IMDB plot summaries. Our dataset encompasses films from the United States, Australia, the United Kingdom, Canada, Japan, China, South Korea, and Russia, along with sixteen other countries, resulting in a total of 24 possible origins. We have a dataset of just under 35,000 training examples.
Let’s look at an excerpt from a movie plot:
Thousands of years ago, Steppenwolf and his legions of Parademons attempt to take over Earth with the combined energies of three Mother Boxes. They are foiled by a unified army that includes the Olympian Gods, Amazons, Atlanteans, mankind, and the Green Lantern Corps. After repelling Steppenwolf ‘s army, the Mother Boxes are separated and hidden in locations on the planet. In the present, mankind is in mourning over Superman, whose death triggers the Mother Boxes to reactivate and Steppenwolf’s return to Earth in an effort to regain favor with his master, Darkseid. Steppenwolf aims to gather the artifacts to form “The Unity”, which will destroy Earth ‘s ecology and terraform it in the image of…
If you haven’t guessed already, this is the plot of Justice League—an American film.
The Results
We trained a range of parameters to examine how the outcomes varied with different data volumes and model sizes. As previously mentioned, BERT’s most significant advantage lies in requiring far less data.
For the LSTM model, we trained the most extensive model our GPU could handle and adjusted the vocabulary size and word length to identify the best-performing configuration. The BERT model, on the other hand, only needed a single layer.
Our testing set remained consistent across all these instances, ensuring that we were consistently evaluating the same training data.
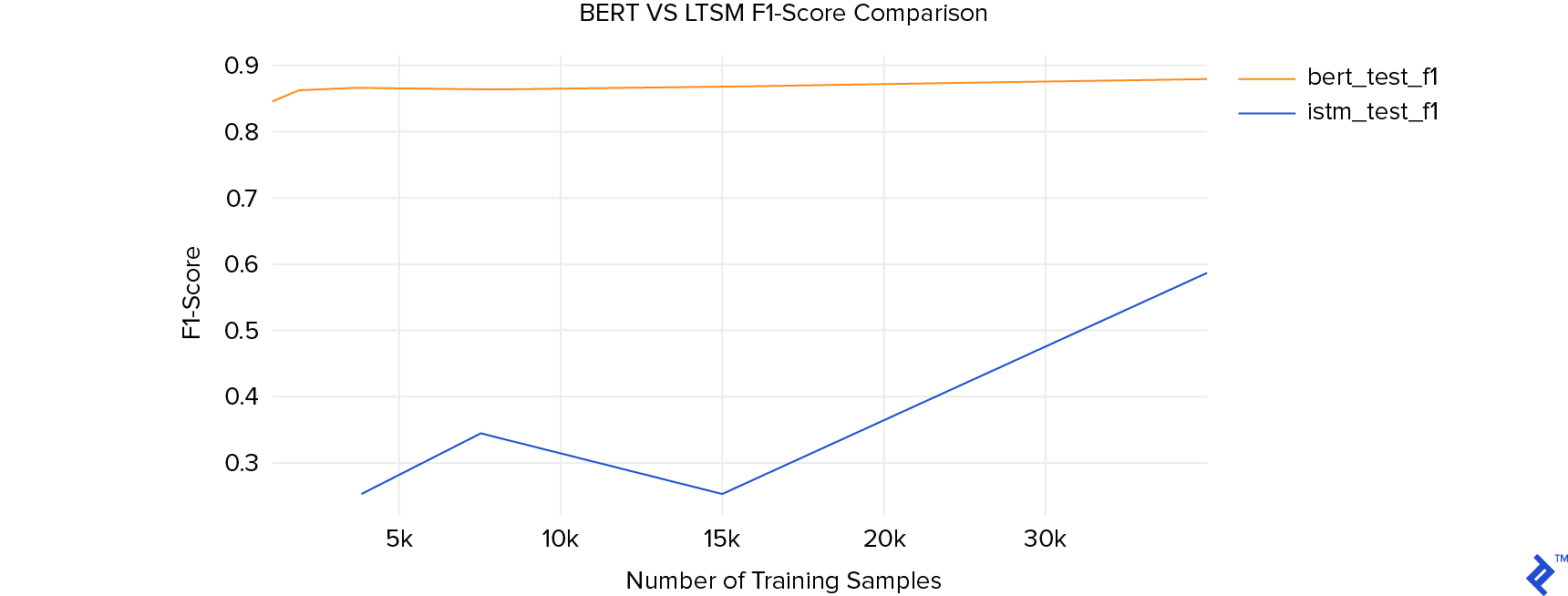
In this specific task, the model trained using BERT sentence encodings achieved a remarkable F1-score of 0.84 after only 1,000 samples. In contrast, the LSTM network’s performance never surpassed an F1-score of 0.60. Even more impressive is the fact that training the BERT models took, on average, one-twentieth of the time required for preparing the LSTM models.
Conclusion
These findings unequivocally highlight a groundbreaking shift in NLP. With 100 times less data and 20 times less training time, we achieved world-class results. The capability to train high-quality models in seconds or minutes, rather than hours or days, unlocks the potential of NLP in areas where it was previously deemed economically unviable.
BERT’s applications extend far beyond the example presented in this article. Multilingual models are available, and it can address a wide array of NLP tasks, either independently as demonstrated here or in combination using multiple outputs. BERT sentence encodings are poised to become a fundamental building block for numerous NLP projects going forward.
The code utilized in this article is accessible on Github. For those interested in exploring further, I highly recommend checking out Bert-as-a-service, which played a pivotal role in generating the BERT sentence encodings used in this analysis.