The majority of newly developed deep learning models, especially in NLP, are exceptionally large, with parameter counts ranging from hundreds of millions to tens of billions.
Generally, the larger the model, a model’s learning capacity increases. As a result, these newer models, possessing vast learning capacity, undergo training on very, very large datasets.
This extensive training enables them to capture the complete data distribution of the datasets they learn from. Essentially, they become repositories of compressed knowledge derived from these datasets. This characteristic unlocks a range of fascinating applications, with transfer learning being the most prevalent. Transfer learning involves fine-tuning pre-trained models on custom datasets/tasks. This method demands significantly less data and results in faster model convergence compared to training from the ground up.
Pre-trained Models: The Algorithms of the Future
While pre-trained models find applications in computer vision, this article will concentrate on their advanced uses within the domain of natural language processing (NLP). Transformer architecture represents the dominant and most potent architecture employed in these models.
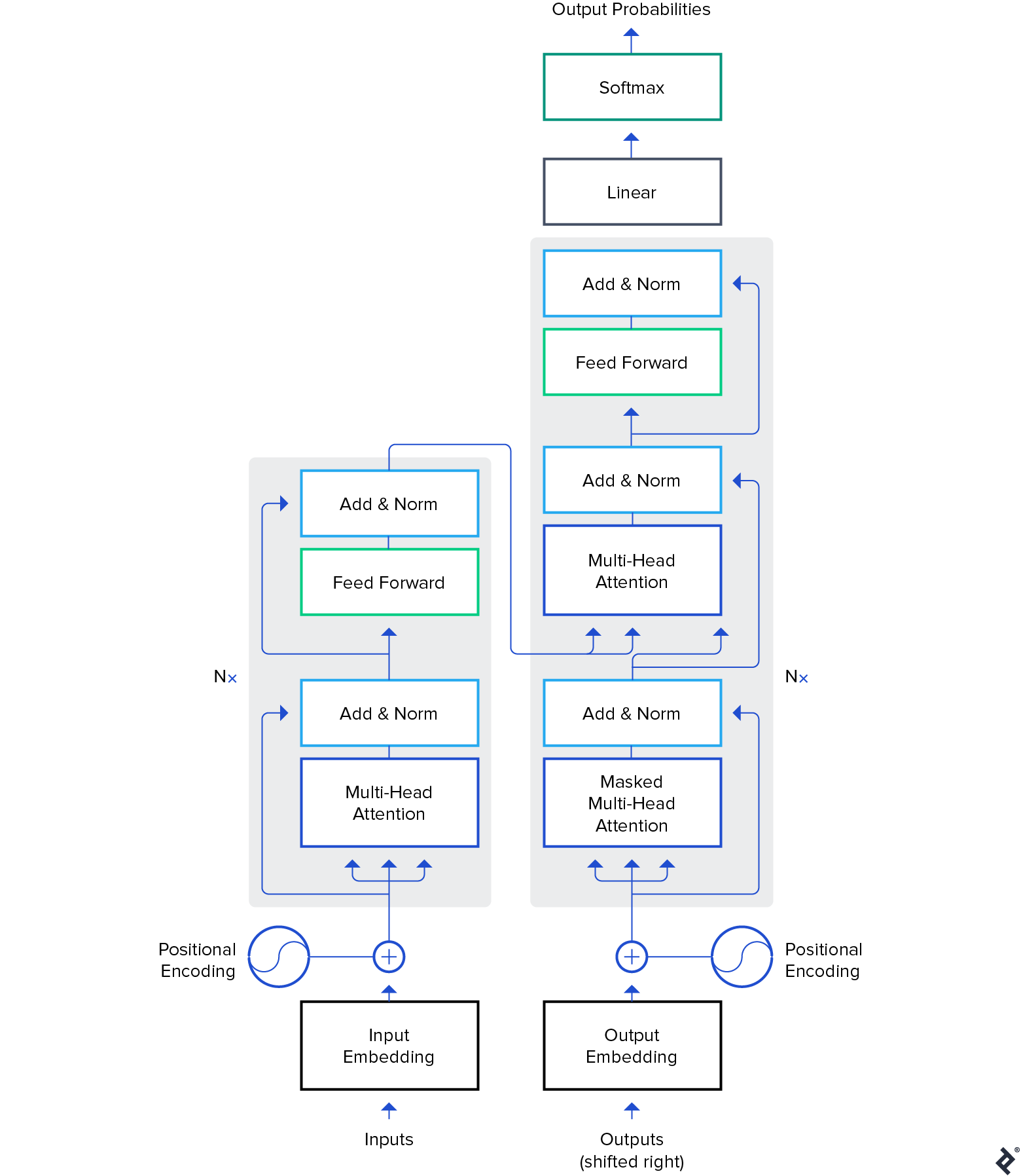
While BERT initiated the NLP transfer learning revolution, our exploration will center around GPT-2 and T5 models. These models are already pre-trained, and fine-tuning them for specific tasks would yield enhanced evaluation metrics. However, our approach will involve using them “out of the box,” without any fine-tuning.
Pre-trained NLP Models: OpenAI’s GPT-2
The release of GPT-2 in 2019 sparked considerable debate. Being very good at generating text, it garnered significant media attention and ignited discussions about the trajectory of AI.
Trained on an expansive 40 GB textual dataset, GPT-2 can be characterized as a very large model containing an immense quantity of condensed knowledge extracted from a diverse range of internet sources.
GPT-2 boasts a multitude of potential use cases. For instance, it excels at predicting the likelihood of a sentence, proving useful for text autocorrection. Moreover, its word prediction capability can be directly employed to build an autocomplete component within IDEs (like Visual Studio Code or PyCharm) to assist in code writing and general text writing. We will leverage it for automatic text generation, and a large collection of text can be utilized for natural language analysis.

Text Generation
The capacity of a pre-trained model such as GPT-2 to generate coherent text is truly remarkable. We can provide it with an initial text fragment (a prefix) and prompt it to generate the subsequent word, phrase, or even an entire sentence.
Consider the task of creating a dataset of product reviews to analyze the types of words commonly found in positive versus negative feedback.
Let’s examine some examples. We’ll begin with a positive prefix: “Really liked this movie!”
| Sample 1 | Loved the character’s emotions at being in constant danger, and how his inner fears were slowly overcome by these events. Also loved that he is so focused on surviving; even for a while it felt like something out of Batman v Superman was showing up every now again because you always knew your enemy would show up eventually anyways :) The ending theme really stuck with me too… I mean yeah they did have to… |
| Sample 2 | It did exactly what I wanted it to do, just a lot of fun. The cast was awesome and the story makes sense so far after seeing everything else already on IMDB. There are hints about being in an underground city from time immemorial due their “power” (or lack thereof) but they don’t really tell that much…I think its more like one big mystery then some other aspects coming together with me for now though….It’s supposed… |
It’s noteworthy that the term review was absent from the prefix. However, since reviews often consist of a title followed by the review content, the model instinctively adapted to this pattern. Additionally, observe the reference to Batman v Superman.
Let’s move on to another illustration. This time, instead of a movie review, we’ll aim to generate a product review using a negative prefix: “A trash product! Do not buy.”
| Sample 1 | And please, do NOT try to use this as a fertilizer for your gardens or lawns – it will cause some serious water damage if ingested by fish and birds. Use with caution because of the possibility that pesticides may be present in pet foods available online at organic grocery stores such too “good” names like Petsmart, PetSmart & Safeway.How toxic is food waste? Waste products can contribute significant amounts - enough so that even very… |
| Sample 2 | No one will give you a piece of that garbage ever again. Just do yourself and your business a favor and clean up before buying it for nothing more than to save some money or convenience in the future.1/2 oz Bottle Plastic Food Storage Packaging + 1 pack #1636370105702615 (P, 3ml) $7 Buy Now You can purchase these bottles at any retail stores but here is how to get… |
Once again, the prefix suggests a product review title, prompting the model to generate text aligned with that format. GPT-2 demonstrates this versatility across various text types.
A Google Colab notebook is available for experimentation, as is the “Write With Transformer” live demo.
Question Answering
Indeed, GPT-2’s training on a vast corpus of web data has equipped it with extensive knowledge encompassing information published online up until 2019. While it handles contextual questions effectively, it necessitates a specific format: “Question: X, Answer:” before attempting autocompletion. Attempting to force an answer to open-ended questions might yield imprecise responses. Let’s test its knowledge with a couple of such questions:
| Sample 1 | Question: Who invented the theory of evolution? Answer: The theory of evolution was first proposed by Charles Darwin in 1859. |
| Sample 2 | Question: How many teeth do humans have? Answer: Humans have 21 teeth. |
As evident, the pre-trained model provided a remarkably detailed response to the first query. For the second, it made a valiant attempt, but its performance pales in comparison to a Google Search.
Clearly, GPT-2 possesses immense potential. Fine-tuning it would enable us to utilize it for the aforementioned examples with significantly improved accuracy. Yet, even in its current pre-trained state, GPT-2 exhibits commendable capabilities.
Pre-trained NLP Models: Google’s T5
Google’s T5 stands out as one of the most sophisticated natural language models currently available. It builds upon prior advancements in Transformer models. Unlike BERT, which solely employed encoder blocks, and GPT-2, which focused on decoder blocks, T5 leverages both.
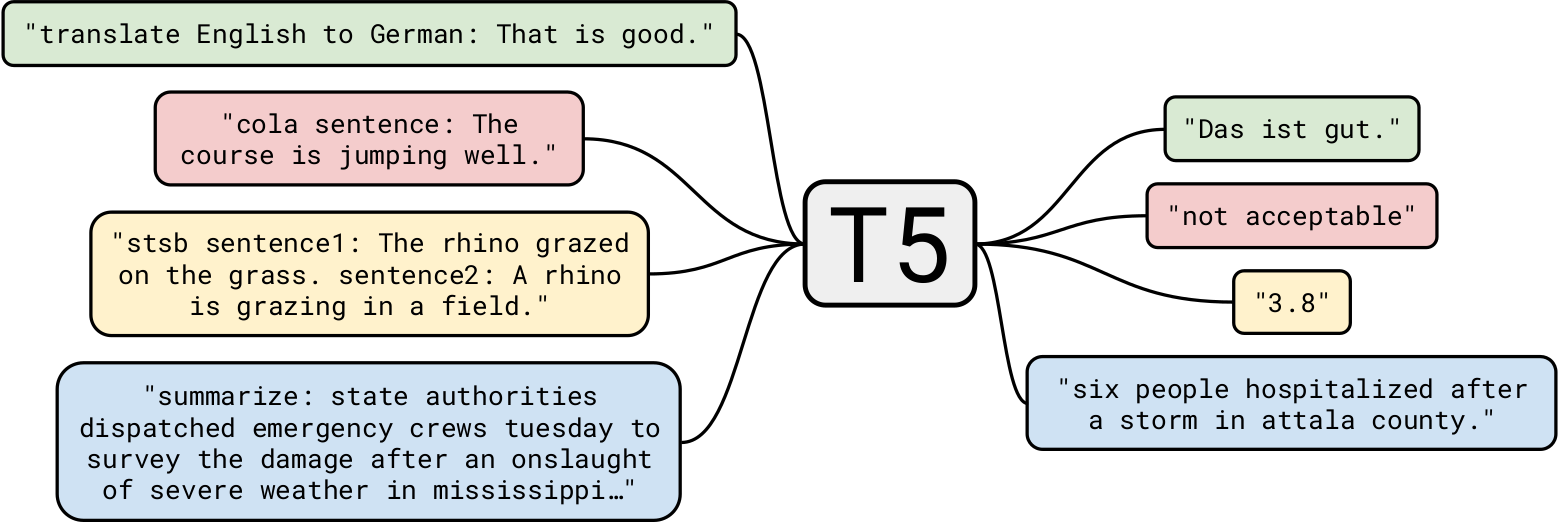
While GPT-2’s training on 40 GB of text data was impressive, T5 was trained on a massive 7 TB dataset. Despite undergoing numerous training iterations, it couldn’t process the entire dataset. Although T5 is capable of text generation tasks similar to GPT-2, we will focus on its application in more compelling business scenarios.
Summarization
Let’s begin with a straightforward task: text summarization](https://paperswithcode.com/task/text-summarization). For those [AI development companies wanting to build an app that summarizes a news article, T5 is perfectly suited for the task. For example, giving this article with T5, here are three distinct summaries it generated:
| V1 | destiny 2’s next season, starting march 10, will rework swords . they’ll have recharging energy used to power both heavy attacks and guarding . the valentine’s day event, crimson days, is also happening this month . |
| V2 | bungie has revealed that the next season of destiny 2 will dramatically rework swords . the studio has mostly been coy about what the season will entail . the rethink will let swords partly bypass ai enemies’ shields . |
| V3 | destiny 2’s next season will rework swords and let them bypass ai enemies’ shields . the season starts march 10th . you can play destiny 2 during crimson days, a valentine’s day event . |
Evidently, T5 excels at summarizing the article, producing different summaries each time.
The application of pre-trained models for summarization holds immense potential. One intriguing use case involves automatically generating summaries for articles, placing them at the beginning for readers seeking a concise overview. This could be further enhanced by personalizing summaries for individual users. For instance, users with limited vocabularies could receive summaries with simpler word choices. This straightforward example illustrates the power of this model.
Another compelling application lies in leveraging such summaries for website SEO. While T5 can be trained to generate high-quality SEO content automatically, utilizing summaries might prove beneficial “out of the box,” without requiring model retraining.
Reading Comprehension
T5 also demonstrates proficiency in reading comprehension tasks, such as answering questions based on a provided context. This capability opens up fascinating use cases, which we’ll delve into later. Let’s start with a few examples:
| Question | Who invented the theory of evolution? |
| Context (Encyclopædia Britannica) | The discovery of fossil bones from large extinct mammals in Argentina and the observation of numerous species of finches in the Galapagos Islands were among the events credited with stimulating Darwin’s interest in how species originate. In 1859 he published On the Origin of Species by Means of Natural Selection, a treatise establishing the theory of evolution and, most important, the role of natural selection in determining its course. |
| Answer | darwin |
Although the text doesn’t explicitly state that Darwin invented the theory, the model drew upon its knowledge and contextual clues to arrive at the correct conclusion.
Let’s try a shorter context:
| Question | Where did we go? |
| Context | On my birthday, we decided to visit the northern areas of Pakistan. It was really fun. |
| Answer | northern areas of pakistan |
That was relatively straightforward. Now, let’s pose a philosophical question:
| Question | What is the meaning of life? |
| Context (Wikipedia) | The meaning of life as we perceive it is derived from philosophical and religious contemplation of, and scientific inquiries about existence, social ties, consciousness, and happiness. Many other issues are also involved, such as symbolic meaning, ontology, value, purpose, ethics, good and evil, free will, the existence of one or multiple gods, conceptions of God, the soul, and the afterlife. Scientific contributions focus primarily on describing related empirical facts about the universe, exploring the context and parameters concerning the “how” of life. |
| Answer | philosophical and religious contemplation of, and scientific inquiries about existence, social ties, consciousness, and happiness |
We understand that this question warrants a complex answer. Nonetheless, T5 managed to produce a reasonably accurate and sensible response. Impressive!
Let’s raise the bar further. We’ll ask questions using the previously mentioned Engadget article as context.
| Question | What is this about? |
| Answer | destiny 2 will dramatically rework |
| Question | When can we expect this update? |
| Answer | march 10th |
Clearly, T5 demonstrates commendable accuracy in contextual question answering. A potential business application involves creating contextual chatbots for websites, capable of addressing queries related to the current page.
Another use case could be searching for specific information within documents, such as posing legal questions like, “Is using a company laptop for personal projects a breach of contract?” using a legal document as context. Despite its limitations, T5 proves quite adept at such tasks.
Readers might wonder, Why not employ specialized models for each task? It’s a valid point. Specialized models would undoubtedly yield higher accuracy and lower deployment costs compared to a pre-trained T5 model. However, T5’s allure lies in its versatility as a “one-size-fits-all” solution. A single pre-trained model can handle for almost any NLP task. Moreover, our objective is to utilize these models directly, without the need for retraining or fine-tuning. Consequently, developers building applications for summarizing articles and performing contextual question answering can rely on the same T5 model for both tasks.
Pre-trained Models: The Deep Learning Models Poised for Ubiquity
This article explored pre-trained models and their “out-of-the-box” applications in various business scenarios. Just as classical sorting algorithms are widely used for sorting problems, these pre-trained models are poised to become standard algorithms. We’ve only scratched the scratching the surface of NLP applications, and these models hold far greater potential.
Pre-trained deep learning models like StyleGAN-2 and DeepLabv3 have the capacity to power, in a similar vein, applications of computer vision. I trust you found this article insightful and welcome your comments below.