While Intel is widely recognized for its significant contributions to technology, particularly its role in the PC revolution with the 8088 processor, it’s not usually the first company that springs to mind for software development. Despite strong competition from AMD and other companies, Intel remains a dominant force in the x86 CPU market. For decades, software engineers have relied on Intel’s hardware platforms, often without delving into the underlying software and firmware. When increased virtualization performance was necessary, developers turned to multicore, hyperthreaded Core i7, or Xeon processors. Similarly, Intel SSDs became the go-to choice for local database experimentation. However, Intel’s ambitions now extend beyond hardware; they are actively encouraging developers to embrace their software offerings as well.
What Is Intel oneAPI?
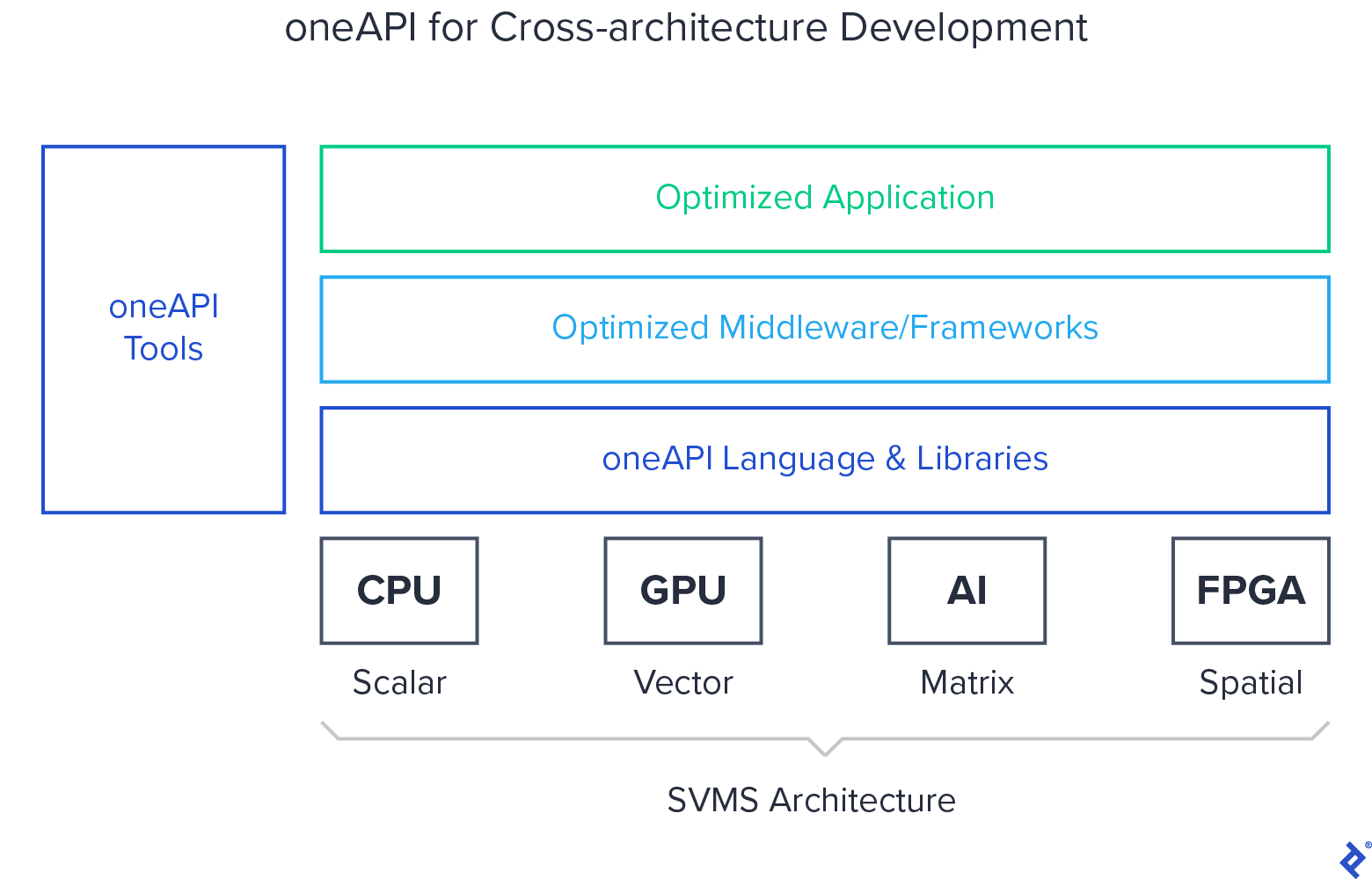
This is where oneAPI comes into play. Intel presents it as a comprehensive, unified programming model designed to streamline development across diverse hardware architectures, including CPUs, GPUs, FPGAs, AI accelerators, and more. Each of these architectures possesses unique characteristics and excels in specific types of operations.
Intel is fully invested in a “software-first” approach and anticipates a strong response from developers. The core principle behind oneAPI is to provide a single platform for a wide spectrum of hardware. This would eliminate the need for developers to use different languages, tools, and libraries when coding for different architectures, such as CPUs and GPUs. With oneAPI, the toolbox and codebase would be consistent across the board.
To achieve this, Intel has developed Data Parallel C++ (DPC++), an open-source counterpart to proprietary languages traditionally used for programming specific hardware (e.g., GPUs or FPGAs). This new programming language is intended to offer the productivity and familiarity of C++ while incorporating a compiler capable of deploying across various hardware targets.
Data Parallel C++ also integrates the Khronos Group’s SYCL to facilitate data parallelism and heterogeneous programming. Intel is currently providing free access to its DevCloud, enabling software engineers to experiment with their tools and explore oneAPI and DPC++ in the cloud effortlessly.
You might be wondering: will it function with hardware from other manufacturers? And what about licensing – is it free? The answer to both questions is a resounding yes. oneAPI is designed to be hardware-agnostic and open-source, and Intel is committed to maintaining these principles.
To delve deeper into oneAPI, we spoke with Sanjiv M. Shah, Vice President of Intel’s Architecture, Graphics and Software Group and general manager of Technical, Enterprise, and Cloud Computing at Intel, to discuss its origins and future direction.
Sanjiv: When considering the components of oneAPI, I categorize it into four key elements. First, we have a language and a standard library. Second, there’s a collection of deep learning tools. The third element is essentially a hardware abstraction layer and a software driver layer that can abstract different accelerators. Lastly, we have a set of domain-focused libraries, such as Matlab. These are the four primary categories within oneAPI. However, we can delve deeper and explore the nine distinct elements that comprise oneAPI. These nine elements essentially consist of the new language we’re introducing, Data Parallel C++, and its accompanying standard library.
Furthermore, there are two learning libraries: one specifically for neural networks and another for communications. We also have the “level zero” library, designed for hardware abstraction, and four domain-specific libraries. We are undertaking this endeavor with a strong emphasis on openness. The specifications for all these components are already publicly available and open. Currently designated as version 0.5, we plan to reach version 1.0 by the end of 2020. We also have open-source implementations for all of these. Our objective is to empower developers to leverage existing resources. If a hardware vendor wishes to implement this language, they can readily utilize our open-source resources as a starting point.
Q: In terms of algorithms and their implementation, how does that aspect function?
Our role is to provide the fundamental building blocks that algorithms rely upon – the underlying mathematical and communication primitives. Typically, algorithm innovation occurs at a higher level, where the focus isn’t on reinventing basic mathematical operations like matrix math, convolution math, and so on. Instead, it’s about discovering novel ways to apply that math and explore new communication patterns. Our primary aim is to furnish the foundational layer, the “level zero,” enabling others to innovate on top of it.
Q: From a hardware perspective, how does it all work?
Let’s consider a hardware provider, for instance, someone developing an AI ASIC. There are two main approaches for this vendor to integrate with and leverage the AI ecosystem. The first option is to implement our low-level hardware interface, which we refer to as “level zero.” By providing their version of level zero adhering to the standard API, they can utilize the open source if desired, and all the software layers above can automatically leverage their implementation.
However, providing the full generality of level zero might be challenging for highly specialized ASICs. As an alternative, they can opt to provide only the math kernels and communication kernels used in our domain and deep learning libraries. In this scenario, we take on the responsibility of “plumbing” those libraries into the higher-level frameworks, automatically integrating them.
Q: You mentioned the current version is designated 0.5, with the complete specification expected by the end of 2020.
Our oneAPI initiative encompasses two parallel tracks. One focuses on the industry aspect, while the other centers on Intel products. The industry specification is currently at version 0.5, and we aim to bring it to version 1.0 around mid-year. Concurrently, Intel is developing a suite of products based on the 0.5 spec, which are currently in beta. By the end of the year, we intend to release version 1.0 products.
Intel’s product offerings extend beyond the nine core elements of oneAPI. In addition to the fundamental programming elements, we also provide essential tools for programmers, such as debuggers, analyzers, and compatibility tools to facilitate migration from existing languages to Data Parallel C++.
Q: What is the transition process like for developers? Is the overall environment similar to what they’re accustomed to?
Yes, the environment is designed to be very familiar. Let me elaborate on Data Parallel C++, as it plays a significant role in our approach. DPC++ can be understood as a combination of three key aspects. It builds upon the foundation of the ISO international standard C++ language. Additionally, there’s a group called Khronos that defines a standard called SYCL, which is layered on top of C++. We leverage SYCL and introduce extensions on top of it. In essence, Data Parallel C++, as we’re building it, is essentially C++ augmented with extensions, similar to SYCL.
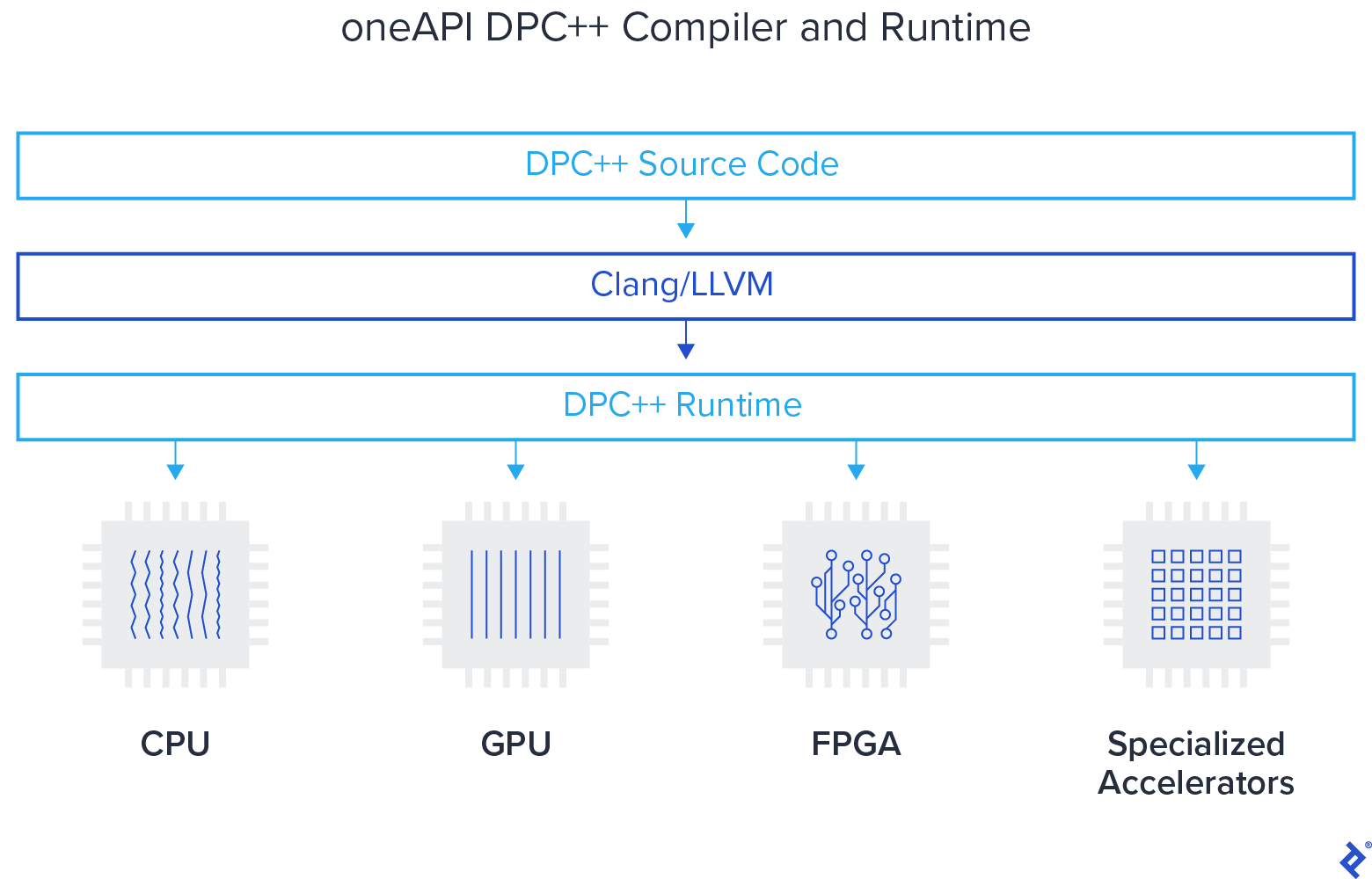
Any C++ compiler can handle the compilation process. The beauty of DPC++ lies in its compatibility with any C++ compiler. However, only a compiler specifically designed for DPC++ can fully leverage its capabilities and generate accelerator code. We’re developing this language with a strong emphasis on openness. All discussions surrounding Data Parallel C++ are conducted within the SYCL committee. The implementations are open-source, all extensions are publicly available, and we’re diligently working to ensure a smooth transition path toward future SYCL standards. Looking ahead, we also envision a seamless integration path into ISO C++ in the next 5-10 years.
Q: Given the compilers and the migration to DPC++, the learning curve shouldn’t pose a significant challenge, should it?
That’s correct. The learning curve will depend on the developer’s starting point, of course. For seasoned C++ programmers, the transition should be relatively smooth. C programmers would need to overcome the hurdle of learning C++, but that’s all. It retains a familiar C++ feel. Similarly, programmers experienced with languages like OpenCL should find it quite similar.
Another crucial point to emphasize is our commitment to open source, utilizing the LLVM infrastructure. All our source code is readily available on the Intel GitHub repository, where you can explore the language implementation and even download an open-source compiler. Furthermore, all of Intel’s tools, including our beta product offerings, are freely accessible for anyone to experiment with and download. We also provide a developer cloud, eliminating the need for downloads or installations, allowing developers to dive straight into coding and exploring the tools we’ve discussed.
Q: While C++ is performant and relatively straightforward, it’s no secret that it’s an aging language with a slow development cycle due to the involvement of numerous stakeholders. Naturally, this wouldn’t be the case with DPC++. You would have much faster iteration cycles and updates, right?
You’ve hit on a critical point for us – the need for rapid evolution that isn’t hampered by the constraints of traditional standardization processes. We value open discussions with the standards community as a pathway for integration, but we also prioritize agility.
Languages thrive when there’s a collaborative design process involving both users and implementers, particularly as architectures evolve. Our goal is to foster a rapid, iterative code design approach where we can experiment, identify best practices, and then standardize them. So, yes, rapid iteration is a key objective for us.
Q: Understandably, some of my colleagues have raised concerns about the concept of “openness” coming from a large corporation. Will DPC++ always remain open to all users and vendors?
Absolutely! The specification is released under a Creative Commons license. Anyone can utilize the spec, fork it if they choose, and contribute to its evolution. It’s important to note that while not every single element of oneAPI is open-source, we are actively working towards making almost all components open-source. All of this is accessible for anyone to leverage and build upon – it’s readily available for implementation.
Codeplay, a company based in the UK, recently announced an Nvidia implementation of DPC++, and we strongly encourage all hardware and software vendors to develop their own ports. We’re at a pivotal moment in the industry where accelerators are becoming increasingly prevalent across multiple vendors. Historically, when a single provider dominated, their language would naturally prevail. However, the software industry demands standardized solutions and a diverse vendor ecosystem.
Our current endeavor mirrors what we achieved roughly two and a half decades ago with OpenMP. At that time, there were numerous parallel languages but no clear leader. We unified them into a standard that, 25 years later, has become the standard for HPC programming.
Q: So, it’s safe to assume that DPC++ will undergo significant evolution in the coming years? What about support for tensors and emerging hardware?
You are absolutely right. The language needs to adapt and support new hardware as it emerges. That’s the driving force behind our emphasis on rapid iteration. Another important aspect is that we’re designing Data Parallel C++ with extensibility in mind. Developers can incorporate architecture-specific extensions when needed.
While our goal is to establish a standard language that can run seamlessly across various architectures, we also recognize that certain use cases demand absolute peak performance. In such cases, developers might need to delve into very low-level programming that might not be portable across architectures. We are building extensions and mechanisms to accommodate this, allowing for extensions, such as those for tensors, that are architecture-specific.
Q: In terms of the code generated for the hardware, how much control do developers have? What about memory management between the system and various accelerators?
We’re adopting the concept of buffers from SYCL, which provides users with explicit control over memory. Additionally, we’re introducing the notion of unified memory. Our aim is to empower programmers with the level of control they need, not just for efficient memory management but also for generating optimized code. Some of the extensions we’re adding to SYCL include features like subgroups, reductions, pipes, and more. These additions will enable developers to generate much more efficient code for different architectures.
Q: The oneAPI distribution for Python, specifically mentioning NumPy, SciPy, and SciKit Learn, is quite interesting. I’m curious about the potential performance gains and productivity benefits that oneAPI could unlock. Do you have any metrics on those aspects?
That’s an excellent question. We are actively supporting the Python ecosystem. Why would Python developers be interested in utilizing an accelerator? It all comes down to extracting better performance from their math and analytics libraries. Our approach involves “plumbing” NumPy, SciPy, SciKit Learn, and others to leverage our optimized libraries and achieve superior performance. When comparing the default implementations of NumPy, SciPy, SciKit Learn, and so on, with properly integrated versions using optimized native packages, the performance gains can be substantial – we’ve observed improvements in the range of 200x to 300x.
Our objective with Python is to achieve performance within a reasonable margin of native code, ideally within 2x or even 80% of native performance. Currently, the state-of-the-art often lags behind by a factor of 10x or more. We want to bridge that gap by carefully integrating high-performance tasks, bringing performance closer to a factor of 2 or even better.
Q: What kind of hardware are we talking about? Can developers unlock this potential on a standard workstation, or would it require something more powerful?
No, these benefits would be accessible across the board. Let’s break down where the gains originate to understand why. Typical Python libraries don’t utilize the virtualization capabilities of CPUs. They don’t fully leverage multi-core capabilities either. They lack optimization, both in terms of memory management and overall code efficiency. Imagine comparing a naively written matrix multiplication routine compiled without optimizations to highly optimized assembly code written by an expert. The performance difference can easily reach several hundredfold. In the Python world, that’s essentially the situation we’re addressing.
Python interpreters and standard libraries operate at such a high level that the resulting code can be quite inefficient. By properly integrating optimized libraries, significant performance gains become achievable. Even a typical laptop today comes equipped with two, six, or even eight CPU cores, often with multithreading and reasonably capable vectorization capabilities, perhaps 256 or 512-bit. So, there’s a lot of untapped performance potential within laptops and workstations. When you scale this up to GPUs, especially with dedicated graphics cards, the potential benefits become even more apparent.
Even integrated graphics solutions are becoming quite powerful. Consider our Ice Lake Gen 11 processors, where the integrated graphics are significantly better than the previous generation. The performance benefits are evident even on laptops.
Q: What about the future of DevCloud availability? If I’m not mistaken, it’s currently free for everyone. Will that remain the case after you reach the gold release next year?
That’s a good question. To be honest, we haven’t finalized that decision yet. However, our current intention is to keep it free indefinitely. It’s intended as a resource for development, experimentation, and exploration. We’ve equipped it with substantial processing power, so developers can run realistic workloads.
Q: So, you wouldn’t mind if, say, a few thousand developers decided to give it a try?
Not at all! We would be thrilled to see that kind of engagement.
To summarize our efforts, we are incredibly enthusiastic about oneAPI. The industry is ripe for a multi-vendor solution, especially given the diverse range of vendors in the market today. Considering our processor lineup, including the upcoming GPUs, increasingly powerful integrated GPUs, and our FPGA roadmap, this is an opportune time to establish a comprehensive standard. Our focus centers on productivity, performance, and building a robust industry infrastructure.
For the three key audiences we’ve discussed – application developers, hardware vendors, and tool and language vendors – oneAPI offers compelling advantages. Application developers can easily leverage readily available resources. Hardware vendors can take advantage of the software stack and seamlessly integrate new hardware. Tool and language vendors benefit from an open-source infrastructure they can adapt and build upon. Intel alone cannot create every language and tool, so we’re fostering an open ecosystem where others can contribute and innovate.