In the rapidly evolving landscape of technology, fields like machine learning, computer vision, API development, and UI design are experiencing remarkable advancements. While the former two delve into the complexities of mathematics and science, the latter two emphasize algorithmic thinking and crafting adaptable architectures. Despite their differences, these domains converge seamlessly in the realm of image processing applications.
This article aims to illustrate how these four areas can be harmoniously integrated to create an image processing application, specifically a straightforward digit recognizer. The simplicity of our chosen application will enable us to grasp the overarching concepts without getting bogged down in intricate details.
We will leverage user-friendly and widely adopted technologies for this endeavor. Python will serve as the backbone for the machine learning aspect, while the interactive front-end will be built using the ubiquitous JavaScript library, React.
Leveraging Machine Learning for Digit Recognition
At the heart of our application lies an algorithm tasked with deciphering handwritten digits, a task we will entrust to the capabilities of machine learning. This form of artificial intelligence empowers systems to learn autonomously from provided data. Essentially, machine learning is about identifying patterns or correlations within data and extrapolating those patterns to make predictions.
Our image recognition process can be broken down into three key stages:
- Procuring images of handwritten digits for training purposes
- Training the system to recognize digits based on the provided training data
- Evaluating the system’s performance using new, unseen data
Setting Up the Environment
To work with machine learning in Python, we require a virtual environment, a practical solution that handles all the necessary Python packages, sparing us from tedious configuration.
Let’s proceed with the installation using the following terminal commands:
| |
Training the Model
Before diving into code, selecting a suitable “teacher” for our machine learning model is crucial. Data scientists often experiment with various models to pinpoint the most effective one. For our purposes, we’ll bypass complex models requiring extensive expertise and opt for the k-nearest neighbors algorithm.
This algorithm excels at categorizing data points on a plane based on specific features. To illustrate, consider the following image:
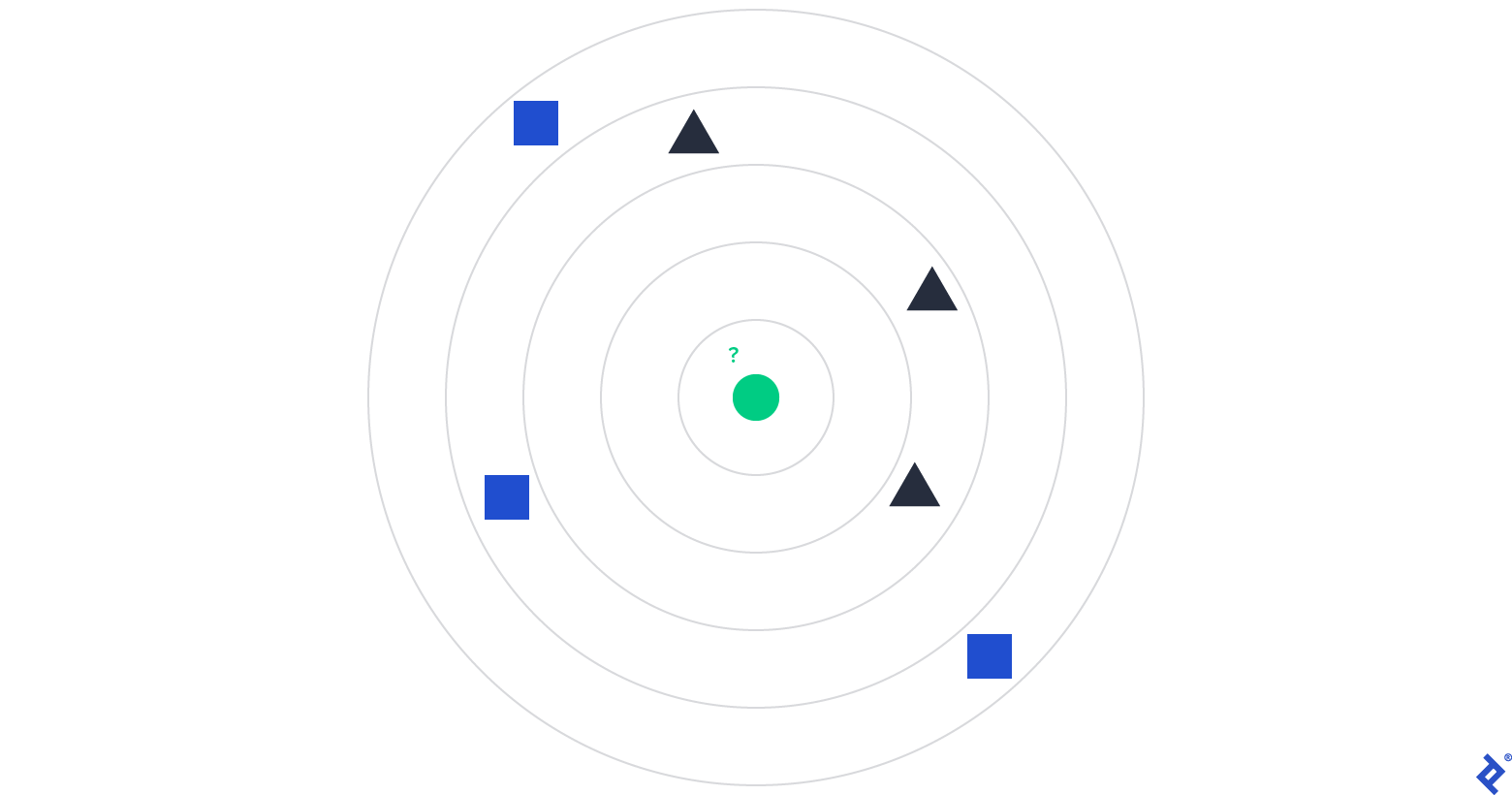
To determine the type of the Green Dot, we examine the types of its k nearest neighbors, where k is a predefined parameter. Referring to the image, if k is set to 1, 2, 3, or 4, the algorithm would classify the Green Dot as a Black Triangle, as most of its closest neighbors fall into that category. However, if we increase k to 5, the majority shifts to Blue Squares, leading to a classification of Blue Square.
To construct our machine learning model, we need several dependencies:
- sklearn.neighbors.KNeighborsClassifier: This is our chosen classifier.
- sklearn.model_selection.train_test_split: This function helps us divide our data into training and testing sets.
- sklearn.model_selection.cross_val_score: This function evaluates the model’s accuracy, with higher values indicating better performance.
- sklearn.metrics.classification_report: This function provides a detailed statistical report of the model’s predictions.
- sklearn.datasets: This package offers access to datasets, including the MNIST dataset we’ll be using.
- numpy: A cornerstone in scientific computing, NumPy enables efficient manipulation of multidimensional arrays in Python.
- matplotlib.pyplot: This package allows us to visualize data.
Let’s start by installing and importing these dependencies:
| |
Next, we load the MNIST Database, a widely used dataset of handwritten digit images frequently employed by those new to machine learning:
| |
With our data loaded, we split it into training and testing sets. We’ll allocate 75% for training our model and reserve the remaining 25% for evaluating its accuracy:
| |
Now, we need to determine the optimal k value for our model to enhance its predictive accuracy. Let’s explore why experimenting with different k values is essential:
| |
Executing this code generates a plot illustrating the algorithm’s accuracy across various k values.
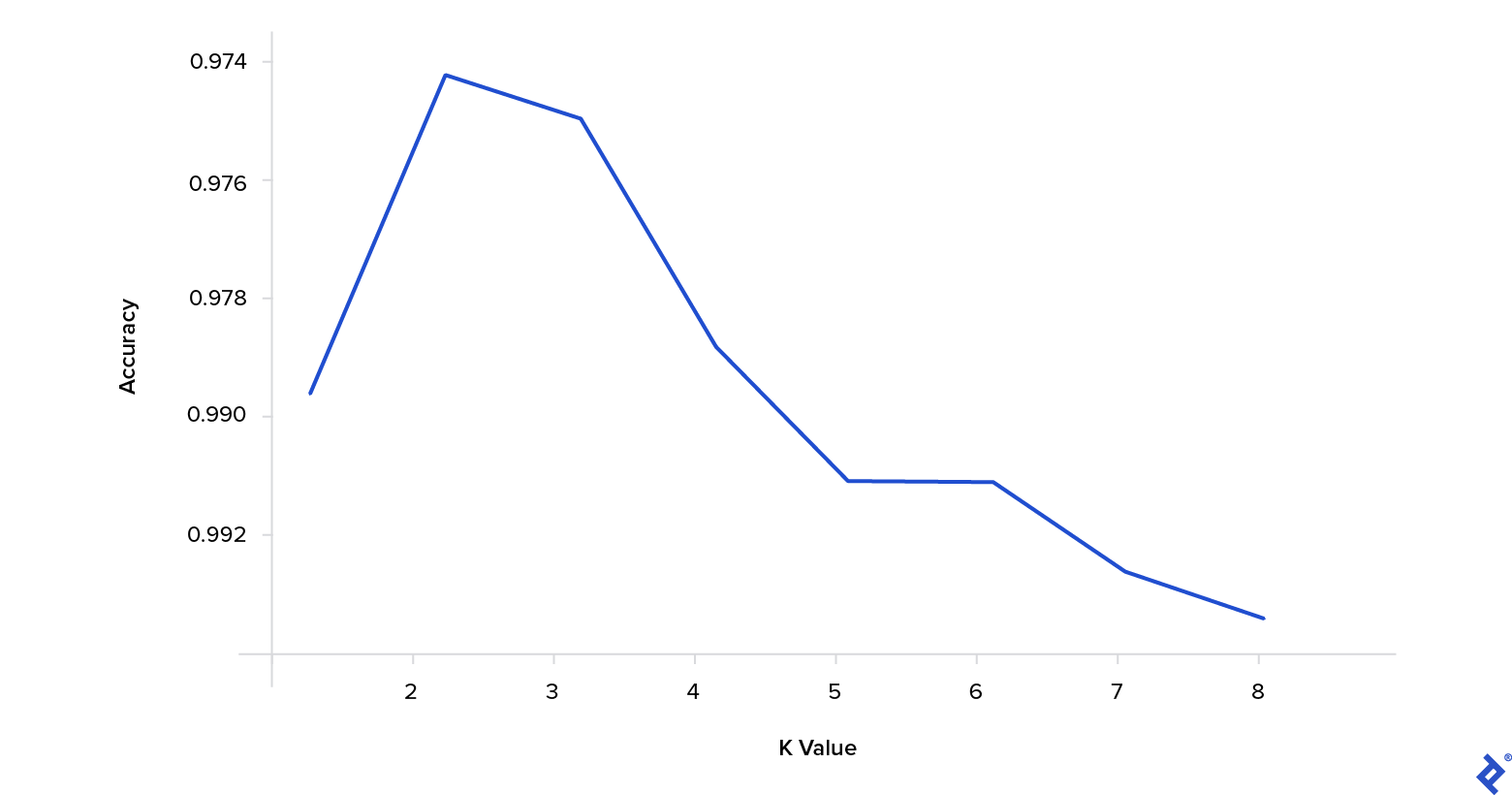
As evident from the plot, a k value of 3 yields the highest accuracy for our chosen model and dataset.
Constructing an API with Flask
Having built the core functionality—an algorithm for predicting digits from images—our next task is to encapsulate it within an API. For this, we’ll utilize the popular and lightweight Flask web framework.
Let’s begin by installing Flask and the necessary image processing dependencies within our virtual environment:
| |
With the installation complete, we create the main entry point file for our application:
| |
This file will contain the following code:
| |
At this stage, we’ll encounter errors indicating that PredictDigitView and IndexView are not defined. To resolve this, we create a file to initialize these views:
| |
This will lead to further errors related to an unresolved import. Our Views package depends on three missing files:
- Settings
- Repo
- Service
Let’s implement each of these.
The Settings module will house configuration settings and constants, including the path to our serialized classifier. This raises a valid question: Why save the classifier?
Storing the trained classifier is a straightforward optimization technique. Instead of retraining the model with each request, we can load the pre-trained version, enabling our app to respond rapidly.
| |
Next, the Repo class provides mechanisms to retrieve and update the trained classifier using Python’s built-in pickle module:
| |
Our API is nearing completion, with only the Service module left to implement. This module handles the following:
- Loading the trained classifier from storage
- Transforming images received from the UI into a format compatible with the classifier
- Performing the prediction using the formatted image
- Returning the prediction result
Let’s translate this logic into code:
| |
Notice that PredictDigitService relies on two dependencies: ClassifierFactory and process_image.
We’ll start by defining a class responsible for creating and training our model:
| |
With our API ready for action, let’s move on to the image processing stage.
Image Processing
Image processing encompasses a range of techniques applied to images to enhance them or extract meaningful information. In our case, we need to seamlessly convert user-drawn images into a format suitable for our machine learning model.
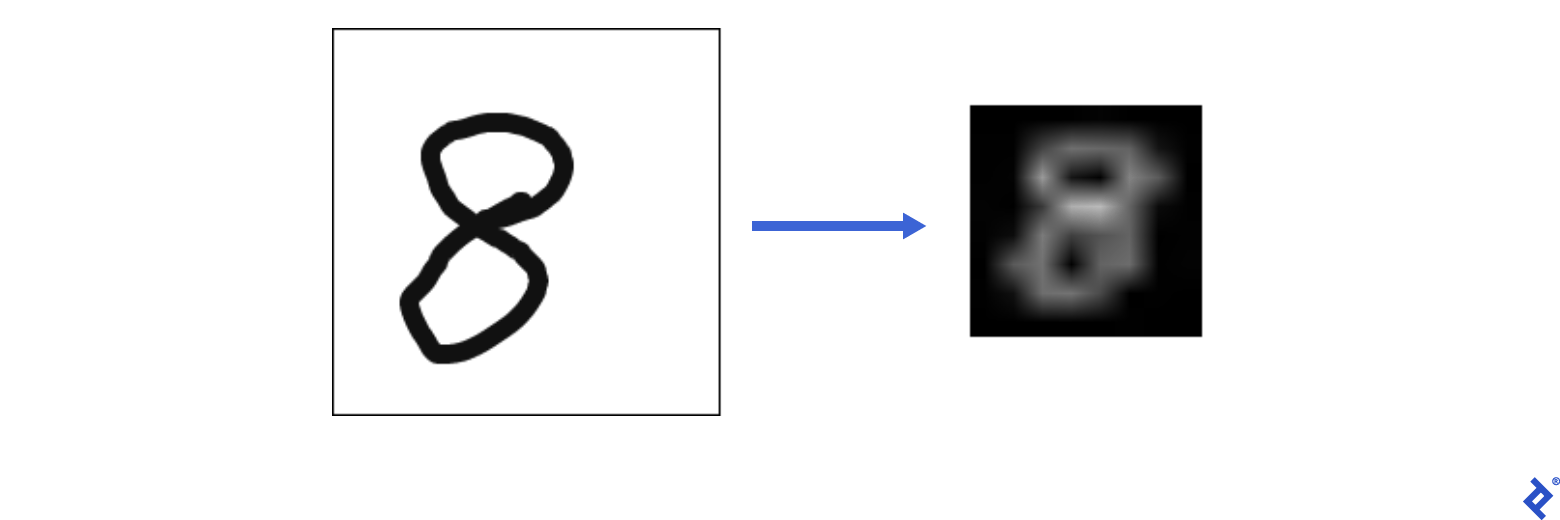
Let’s import some helper functions to achieve this:
| |
We can break down this image transformation process into six steps:
1. Replacing Transparent Backgrounds with Color

| |
2. Trimming Excess Borders

| |
3. Adding Uniform Borders

| |
4. Converting to Grayscale
| |
5. Inverting Colors

| |
6. Resizing to 8x8 Format

| |
Now, it’s time to test our application. After starting the application, use the command below to send a request with this iStock image to the API:

| |
| |
You should see the following output:
| |
Our application successfully identified the digit ‘8’ from the sample image.
Building a Drawing Interface with React
To quickly set up the front-end, we’ll use CRA boilerplate:
| |
Next, we need a dependency for drawing digits. The react-sketch package perfectly suits our requirements:
| |
Our application comprises a single component with two main aspects: logic and view.
The view is responsible for rendering the drawing canvas, along with Submit and Reset buttons. It also displays predictions or errors. On the logic side, we handle image submission and sketch clearing.
Clicking Submit triggers the extraction of the drawn image, which is then sent to the API’s makePrediction function. Successful requests update the prediction state, while errors are reflected in the error state.
Clicking Reset clears the drawing canvas:
| |
With the logic in place, let’s add the visual elements:
| |
Our component is now complete. To test it, execute the following command and navigate to localhost:3000 in your web browser:
| |
A live demo of the application is accessible here. You can also explore the source code on GitHub.
Conclusion
While the accuracy of our digit classifier might not be flawless, that was not our primary objective. The disparity between the training data and user-drawn input is significant. Nonetheless, we managed to build a functional application from scratch in under 30 minutes.

Through this process, we gained valuable experience in:
- Machine learning
- Back-end development
- Image processing
- Front-end development
Software capable of recognizing handwritten digits finds applications in diverse domains, from education and administration to postal and financial services.
Hopefully, this article inspires you to further explore machine learning, image processing, and front-end and back-end development, using these skills to craft innovative and impactful applications.
For those interested in deepening their understanding of machine learning and image processing, our Adversarial Machine Learning Tutorial is a valuable resource.