The adage “Two heads are better than one” takes on a whole new meaning in the world of machine learning ensembles. These methods are some of the most successful in Kaggle competitions, frequently claiming victory with their remarkable performance.
This power of collective intelligence was recognized long before Kaggle, over a century ago, by statistician Sir Francis Galton. He observed a competition at a livestock fair where people guessed an ox’s weight. With 800 participants, ranging from experienced farmers to clueless city dwellers, Galton assumed the average guess would be wildly inaccurate.
However, he was astonished to find turned out. In a surprising turn of events, the average guess was off by less than a pound (< 0.1%), while even the most accurate individual predictions were significantly off.
This unexpected outcome begs the question: what made it possible?
Why are Machine Ensembles so Effective?
The event that challenged Galton’s assumptions highlights what makes ensembles so potent: diverse and independent models, trained on different subsets of data for the same task, perform better collectively than individually. Why? Because each model learns a different facet of the concept, resulting in varied valid results and errors based on its unique “knowledge.”
The beauty lies in how these individual strengths complement each other, while errors effectively cancel each other out:

The key is to train high-variance models, like decision trees, on distinct data subsets. This allows each model to overfit to its specific data, but when combined, the variance magically disappears, yielding a new, more robust model.
Just like in Galton’s observation, aggregating data from various sources leads to a result that’s “smarter” than any isolated data point.
Ensemble Learning in Action: A Look at Kaggle Competitions
In the Otto Group Product Classification Challenge, participants were tasked with building a predictive model capable of classifying main product categories.
A prime example of ensemble success is the winning model was built, a three-layered stacking ensemble. The first layer consisted of 33 models, the second added three more (XGBoost, a neural network, and AdaBoost), and the final layer calculated the weighted mean of the previous outputs. This demonstrates the complexity and effectiveness of ensembles.
Another notable example is Chenglong Chen’s winning model for the Crowdflower Search Results Relevance competition, which involved predicting the relevance of search results. While you can explore the complete explanation of his method, the key takeaway regarding ensembles is that the winning solution employed an ensemble of 35 models, many of which were ensembles themselves – a meta-ensemble.
Exploring Ensemble Methods
There are numerous ways to implement ensemble methods in machine learning. Let’s delve into some popular ones:
- Bagging
- Random Forest
- Boosting
- AdaBoost
- Gradient Boosting and XGBoost
- Hybrid Ensemble Methods
- Voting
- Stacking
- Cascading
Bagging
As previously mentioned, training multiple models on different data subsets is crucial. In reality, acquiring sufficient high-quality data for numerous models can be challenging. This is where bagging (bootstrap aggregating) comes in. It utilizes bootstrapping – random sampling with replacement – to create overlapping data subsets.
Once your ensemble models are trained, the final prediction is generated by aggregating individual model predictions using a chosen metric like mean, median, or mode. Weighted metrics based on model prediction probabilities can also be employed:
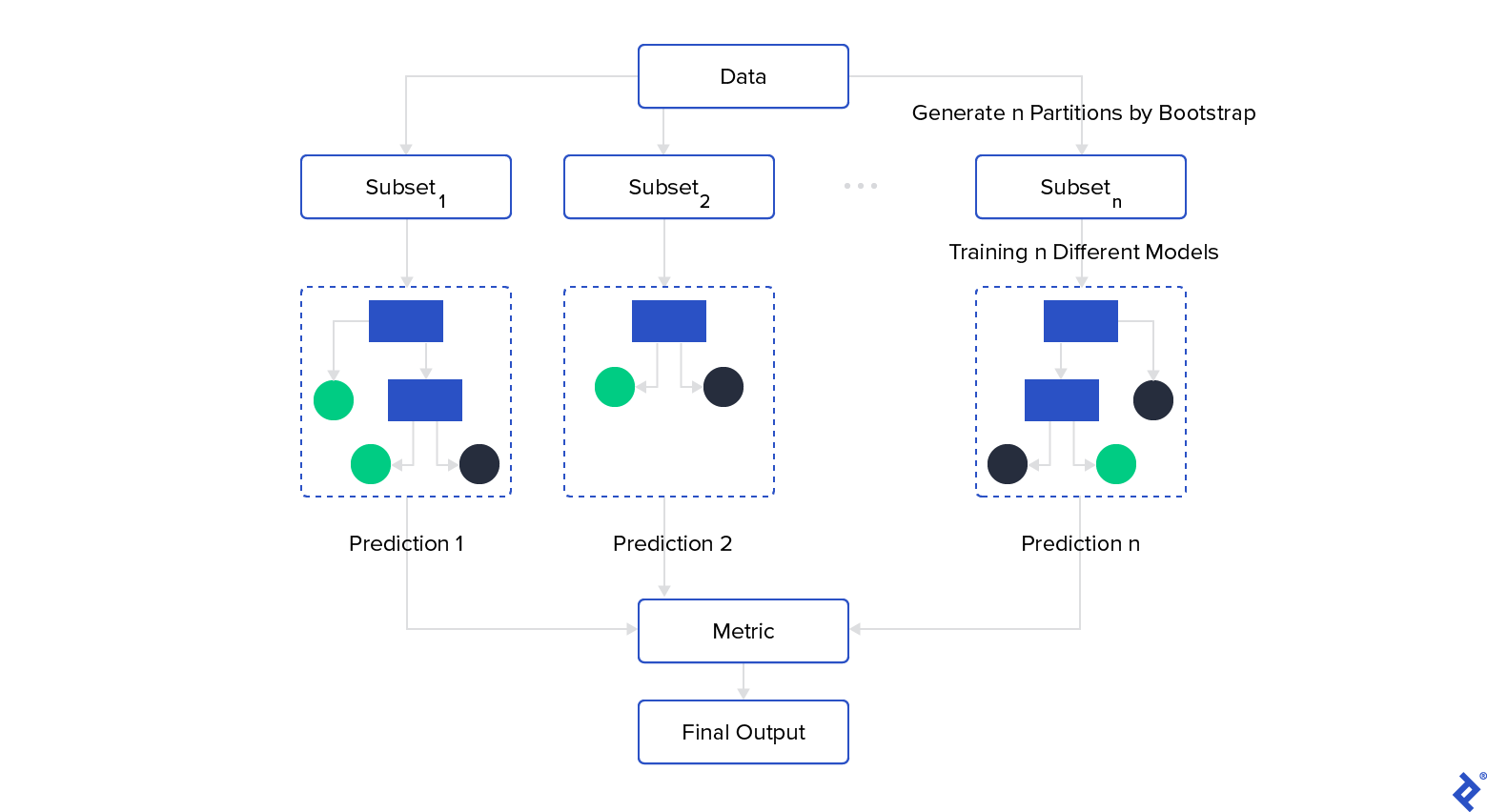
However, using decision trees as models with limited strong predictive attributes can lead to similar trees. This is because identical attributes tend to occupy the root node, resulting in similar predictions across branches.
Random Forest
To address this issue, random forest comes into play. This bagging ensemble utilizes trees but restricts each node to a random subset of attributes. This enforces model diversity and makes random forest highly effective for feature selection.
The popularity of random forest stems from its ability to deliver good performance with low variance and training time.
Boosting
Like bagging, boosting leverages bootstrapping for model training. However, it introduces weights to instances based on model prediction errors. Unlike the parallel nature of bagging, boosting operates sequentially, with each model having access to previous model predictions through weighted probabilities.
Boosting aims to improve overall performance by focusing on misclassified instances:
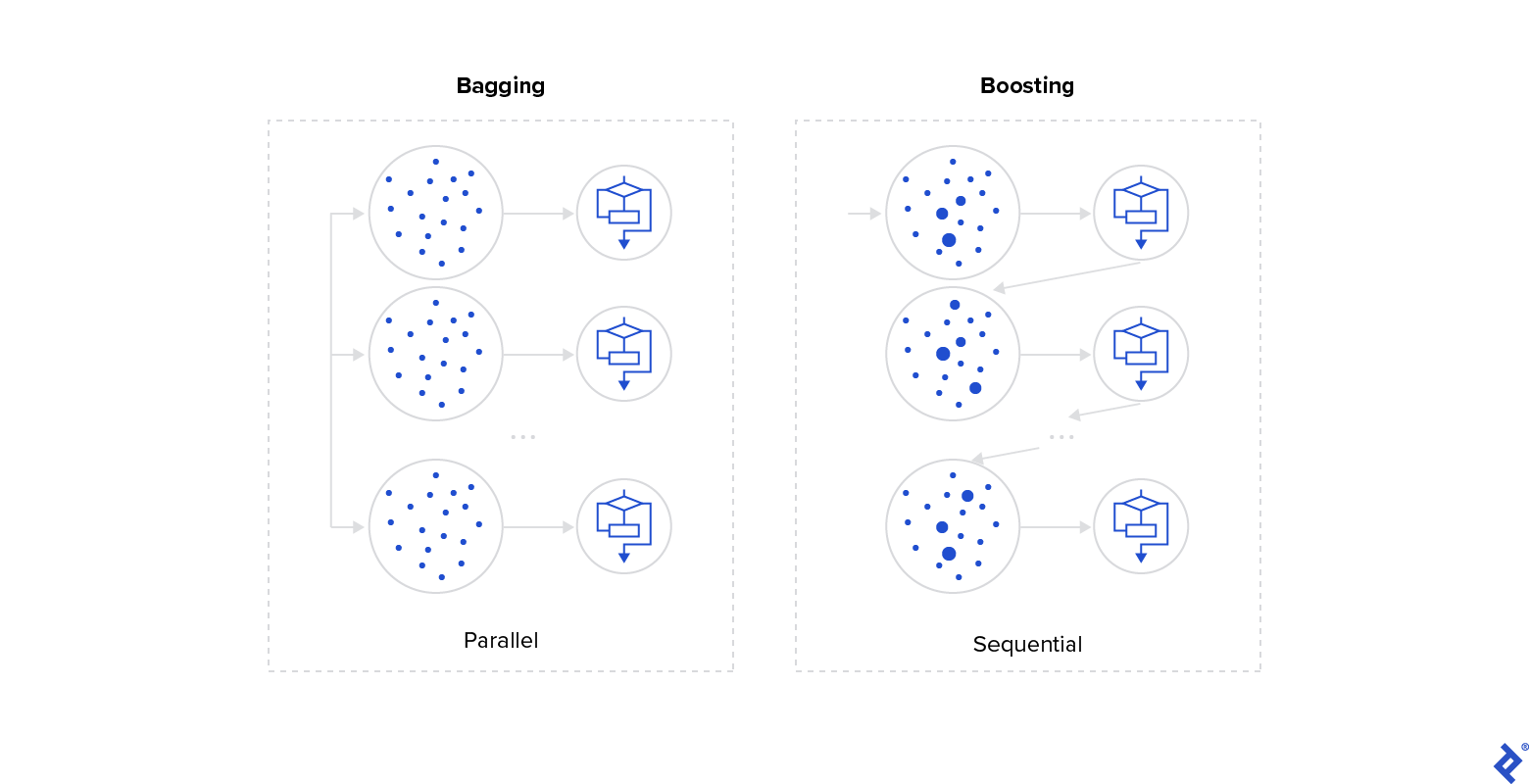
It assigns weights to models as well, prioritizing those with better training performance during the prediction phase.
Let’s examine popular boosting models:
AdaBoost
As one of the earliest boosting implementations, AdaBoost closely follows the general boosting principles and employs decision trees. Here’s a simplified explanation of the training phase:
| |
During prediction, each prediction is weighted based on its calculated error rate e[t], giving less weight to inaccurate results.
Gradient Boosting and XGBoost
Finding the optimal hyperparameter configuration for multiple interacting models poses a significant challenge. Gradient boosting offers an elegant solution by defining a loss function that considers all model hyperparameters and outputs the overall ensemble error. Using gradient descent, it identifies the function’s minimum value (lowest error), thus determining the best hyperparameter configuration for each model.
However, this introduces a scaling problem, which is addressed by XGBoost (extreme gradient boosting), the reigning champion for structured data. This highly efficient gradient boosting implementation leverages techniques like parallelized computing, built-in cross-validation, regularization, and hardware optimization to deliver exceptional performance.
XGBoost gained prominence when its creator used it to win a Kaggle challenge by a large margin. Its subsequent open-source release and Python wrapper propelled it into the limelight as an ML champion.
Hybrid Ensemble Methods
Why limit ourselves to ensembles with the same model type? Combining different models effectively leads to even more powerful ML methods: hybrid ensembles.
Voting
Voting is a straightforward approach where multiple trained models “vote” during prediction:

Model weights can be assigned based on performance or prediction probabilities to generate a weighted vote.
Stacking
Stacking takes voting a step further by introducing a meta-learning layer on top of base models for final prediction. This layer learns from model predictions instead of directly from the data:
Stacking allows for unlimited meta-layers, resulting in multi-level models. Decision trees, SVMs, or perceptrons are recommended for stacked models, while base models can be anything, even other ensembles, creating an ensemble of ensembles. Stacking excels with base models like decision trees that provide both value predictions and their probabilities.
Despite its potential to outperform bagging and boosting, stacking is less popular due to its complex interpretability and vast configuration possibilities. However, the right model combination can unlock its true power.
Cascading
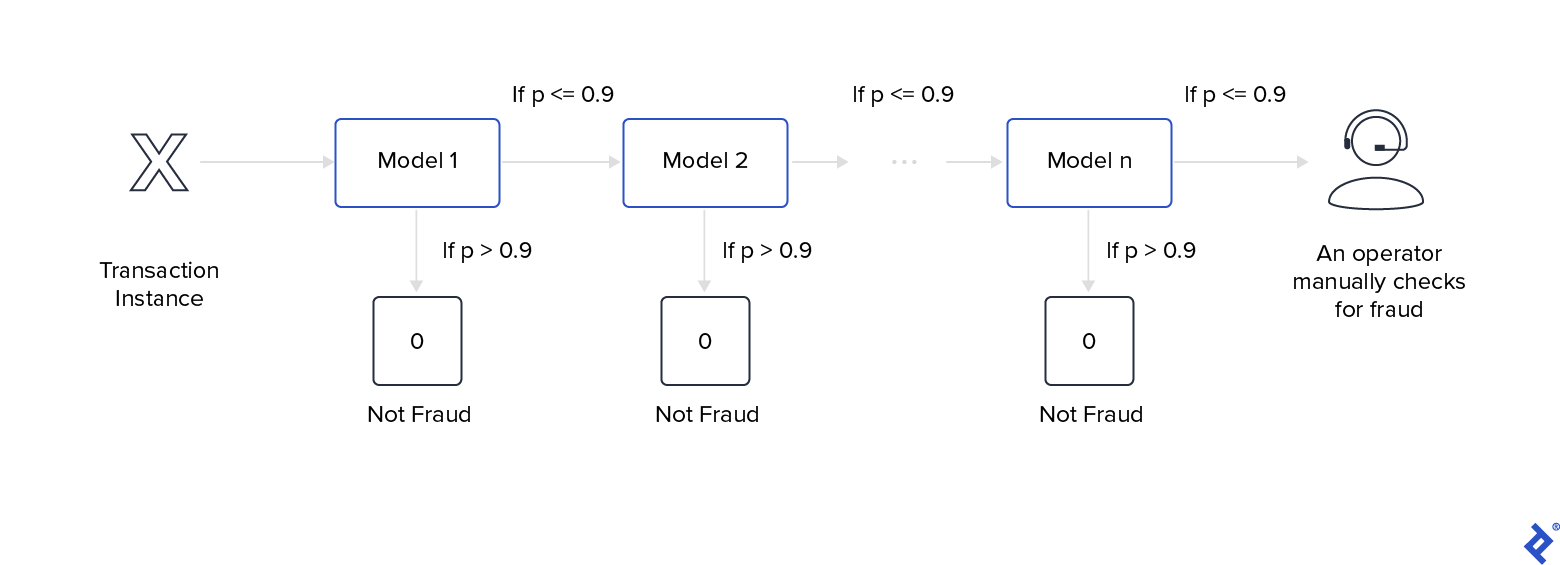
Cascading is ideal for scenarios requiring high prediction certainty. It employs a stacking approach with only one model per layer. Each layer’s models discard instances deemed unlikely to belong to the target class.
Cascading allows simpler models to evaluate data before complex ones. In the prediction phase, the first model processes the data and passes it to the next layer only if its certainty is below a high threshold (e.g., greater than 0.9). Otherwise, the cascade returns the current model’s prediction. If no layer achieves sufficient certainty, the ensemble defaults to the negative class.
A classic use case is fraud detection, where millions of daily transactions cannot be manually verified. Cascading can confidently discard non-fraudulent transactions, leaving a manageable subset for manual review:

These models are excellent choices when prioritizing the recall metric.
Unlike the multi-expert approach of voting and stacking, cascading utilizes a multistage approach. However, excessive depth can lead to overfitting.
The Power of Collaboration: Ensemble Methods
Combining multiple models, much like human collaboration, allows for the creation of superior and more robust predictors. We explored three ensemble families – bagging, boosting, and hybrids – and their training and prediction mechanisms.
While a single decision tree can be weak and unstable, an ensemble of diverse trees (random forest) becomes a highly accurate and stable predictor. Ensembles excel at constructing models with low variance and bias, overcoming a major machine learning trade-off. In many cases, they outperform other methods, even surpassing deep learning, except when dealing with unstructured data.
Compared to deep neural networks, ensembles tend to be lighter, faster to train and test, and require less demanding hardware.
However, the inner workings of ensembles, with their multitude of models, can be challenging to interpret. Thankfully, techniques like LIME provide interpretable explanations for individual instance predictions across various machine learning models.
Kaggle competitions serve a greater purpose than just fun, learning, and prizes. They drive the development of powerful models for real-world applications, addressing critical issues like fraud detection in finance and other high-stakes domains.
Ensembles deliver superior predictions with lower variance and bias compared to other models. However, their interpretability can be challenging, which is crucial in sensitive applications like loan approvals, where clear explanations are necessary.
Whether you’re building enterprise-grade ML models or competing for recognition, ensembles should be your go-to tool for creating powerful predictors.