You may have heard of GraphQL, a new way to fetch APIs that offers an alternative to REST. Initially an internal Facebook project, it has gained significant a lot of traction since being open sourced.
This article aims to ease your transition from REST to GraphQL, whether you’re already convinced or just curious. While no prior GraphQL knowledge is needed, some REST API familiarity is assumed.
We’ll start by outlining three reasons why GraphQL surpasses REST. Afterward, a tutorial demonstrates adding a GraphQL endpoint to your back-end.
GraphQL vs. REST: Why Choose GraphQL?
For a comprehensive and unbiased comparison, refer to the extensive “REST vs. GraphQL” overview available here. However, let’s delve into my top three reasons for preferring GraphQL.
Reason 1: Enhanced Network Performance
Consider a back-end user resource with numerous fields (first name, last name, email, etc.). Clients typically require only a few of these.
REST’s /users endpoint fetches all user fields, even if the client uses only a subset. This data transfer inefficiency, especially noticeable on mobile, is mitigated by GraphQL’s default minimal data fetching. You specify only the required fields, such as first and last names.
GraphiQL, an API explorer for GraphQL, is showcased below using a project created for this article. The code, hosted on GitHub, will be examined later.
The left pane displays the query fetching all users (GET /users in REST) with only their first and last names.
Query
| |
Result
| |
Fetching emails requires simply adding an “email” line below “lastname”.
Some REST back-ends offer partial resource retrieval via options like /users?fields=firstname,lastname. While helpful, Google recommends it, it’s not a standard feature and compromises readability, especially with additional query parameters like:
&status=activefor filtering active users&sort=createdAatfor sorting by creation date&sortDirection=descfor descending order&include=projectsfor including user projects
These parameters are essentially REST API patches mimicking a query language. In contrast, GraphQL, inherently a query language, ensures concise and precise requests from the outset.
Reason 2: Simplifying the “Include vs. Endpoint” Dilemma
Imagine a project management tool with users, projects, and tasks, and these relationships:
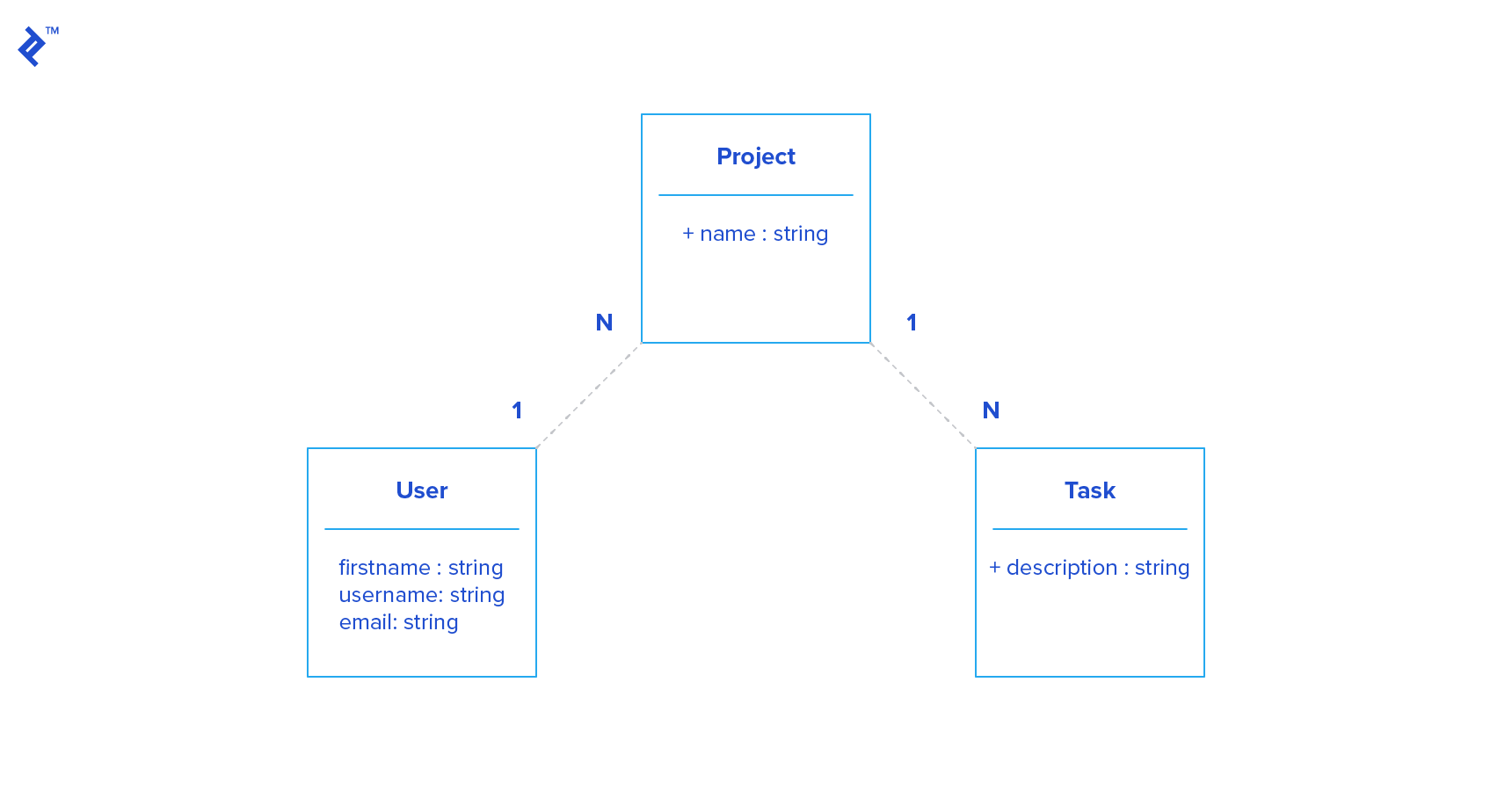
Here are some possible endpoints:
| Endpoint | Description |
|---|---|
GET /users | List all users |
GET /users/:id | Get the single user with id :id |
GET /users/:id/projects | Get all projects of one user |
While organized and readable, complexity arises with intricate requests. For instance, displaying only project titles on the home page but projects and tasks on the dashboard without multiple calls to GET /users/:id/projects necessitates:
GET /users/:id/projectsfor the home pageGET /users/:id/projects?include=tasks(for example) on the dashboard, appending tasks
Adding ?include=... parameters, even recommended by the JSON API specification, eventually leads to unwieldy expressions like ?include=tasks,tasks.owner,tasks.comments,tasks.comments.author.
A dedicated /projects endpoint (/projects?userId=:id&include=tasks) might seem appealing, but determining the optimal approach can be challenging, even more complicated particularly with many-to-many relationships.
GraphQL consistently utilizes the include mechanism, providing a robust and uniform syntax for fetching relationships.
Fetching all projects and tasks for user ID 1 illustrates this:
Query
| |
Result
| |
The query remains readable even with deeper nesting for tasks, comments, pictures, and authors. GraphQL simplifies complex object fetching.
Reason 3: Effortless Handling of Diverse Clients
Back-end development often starts with maximizing API usability. However, clients often demand more data with fewer calls. Deep includes, partial resources, and filtering lead to divergent requests from web and mobile clients.
REST offers solutions like custom endpoints (e.g., /mobile_user), custom representations (Content-Type: application/vnd.rest-app-example.com+v1+mobile+json), or even client-specific APIs (like Netflix once did). All require additional effort from back-end developers.
GraphQL empowers clients to construct complex queries independently, allowing varied consumption of the same API.
Getting Started with GraphQL
The “GraphQL vs. REST” debate often mistakenly implies an either/or choice. In reality, modern applications use various services with multiple APIs. GraphQL can serve as a gateway or wrapper for these services. Clients interact with the GraphQL endpoint, which communicates with databases, external services (ElasticSearch, Sendgrid), or other REST endpoints.
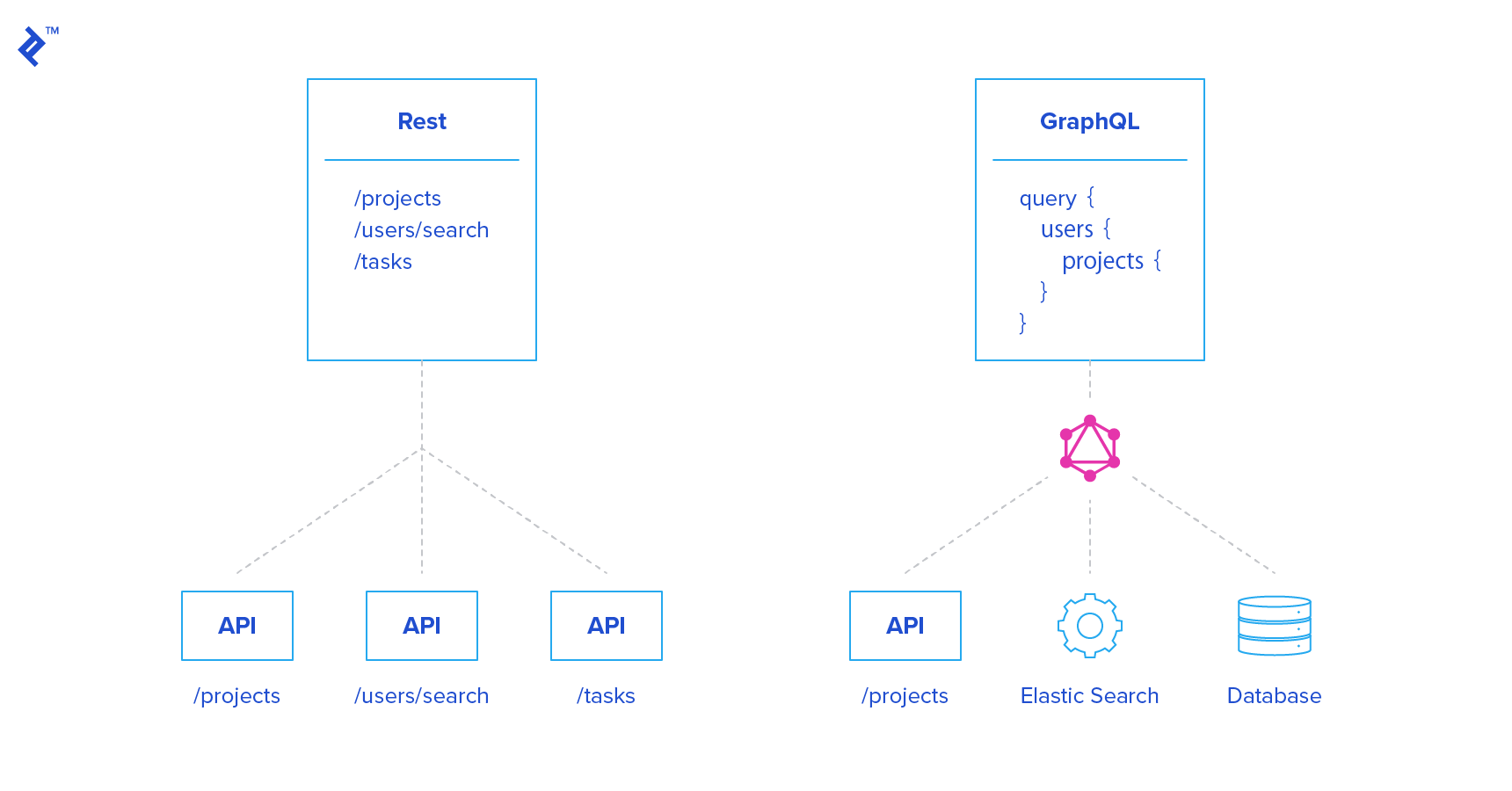
Alternatively, a separate /graphql endpoint can be added to an existing REST API. This allows experimenting with GraphQL without disrupting existing clients or infrastructure, which is our approach in this tutorial.
Our example project, a simplified project management tool (available on GitHub), utilizes Node.js, Express, SQLite, and Sequelize. The models (user, project, task) are defined in the models folder, and REST endpoints (/api/users*, /api/projects*, /api/tasks*) are defined in the rest folder.
* Note: Since publication, Heroku’s free hosting discontinuation has rendered the demos inaccessible.
It’s crucial to understand that GraphQL can be implemented with any back-end, database, or programming language. Our choices here prioritize simplicity.
Our objective is to implement a /graphql endpoint that bypasses REST endpoints, fetching data directly from the ORM for independence.
Types
GraphQL uses strongly typed types to represent the data model, ideally mirroring your existing models. Our User type would be:
| |
Queries
Queries define executable GraphQL API queries. A RootQuery conventionally houses all queries. REST equivalents are indicated for clarity:
| |
Mutations
Analogous to POST/PATCH/PUT/DELETE requests, mutations are essentially synchronized queries.
We’ll group mutations within a RootMutation:
| |
Notice the new UserInput, ProjectInput, and TaskInput types, mirroring REST’s practice of input data models for resource creation and updates. UserInput is a subset of User without id and projects, using the keyword input:
| |
Schema
The GraphQL schema, exposed by the GraphQL endpoint, is defined using types, queries, and mutations:
| |
This strongly typed schema enables helpful autocompletes in GraphiQL*.
* Note: The article’s demos are no longer accessible due to Heroku’s discontinued free hosting.
Resolvers
Resolvers define the actions performed for each query/mutation. They can:
- Call internal REST endpoints
- Invoke microservices
- Interact with the database for CRUD operations
We’ll opt for the third option. Let’s examine our resolvers file:
| |
This means a user(id: ID!) query triggers a database lookup using Sequelize’s User.findById() ORM function.
Joining models requires defining additional resolvers:
| |
Requesting the projects field in a User type appends this join to the database query.
Finally, resolvers for mutations:
| |
You can explore this interactively here. To maintain data integrity, mutation resolvers are disabled, preventing database create, update, or delete operations (returning null on the interface).
Query
| |
Result
| |
Rewriting existing types, queries, and resolvers can be time-consuming. Fortunately, tools like there are tools automate SQL schema translation to GraphQL, including resolvers!
Assembling the Pieces
With a defined schema and resolvers, mounting a /graphql endpoint becomes straightforward:
| |
This enables a visually appealing GraphiQL interface* on your back-end. To make requests without GraphiQL, copy the request URL (e.g., https://host/graphql?query=query%20%7B%0A%20%20user(id%3A%202)%20%7B%0A%20%20%20%20firstname%0A%20%20%20%20lastname%0A%20%20%20%20projects%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%20%20tasks%20%7B%0A%20%20%20%20%20%20%20%20description%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D*) and execute it using cURL, AJAX, or directly in the browser. Of course, dedicated GraphQL clients can simplify query construction. See below for examples.
* Note: Heroku’s free hosting discontinuation has rendered the demos inaccessible.
Next Steps
This article provided a glimpse into GraphQL and demonstrated its integration alongside existing REST infrastructure. The best way to assess its suitability is through hands-on experimentation.
Numerous features, such as real-time updates, server-side batching, authentication, authorization, client-side caching, and file uploading, warrant further exploration. How to GraphQL offers an excellent starting point.
Additional resources:
| Server-side Tool | Description |
|---|---|
graphql-js | The reference implementation of GraphQL. You can use it with express-graphql to create a server. |
graphql-server | An all-in-one GraphQL server created by the Apollo team. |
| Implementations for other platforms | Ruby, PHP, etc. |
| Client-side Tool | Description |
|---|---|
| Relay | A framework for connecting React with GraphQL. |
| apollo-client. | A GraphQL client with bindings for React, Angular 2, and other front-end frameworks. |
In conclusion, GraphQL is more than just hype. While not an immediate REST replacement, it presents a performant solution to a real problem. Despite its relative infancy and evolving best practices, GraphQL is undoubtedly a technology to watch in the coming years.