Computers excel at automating human tasks, from simple ones like moving objects to more complex tasks requiring decision-making in challenging scenarios. This is where machine learning comes in.

Traditionally, algorithms relied on expert knowledge and rules. However, the rise of computing power and vast datasets has led to a shift towards computational approaches.
Neural networks have gained immense popularity in machine learning, leading many to believe they are a universal solution. However, this is far from the truth. From a statistician’s perspective, neural networks are just one type of inference approach with strengths and weaknesses, and their suitability depends on the problem.
Often, there are more effective methods available.
This article presents a framework for tackling machine learning problems. While it won’t delve into specific models, it aims to show why you shouldn’t always default to “neural network” when facing such problems.
Pros and Cons of Neural Networks
Neural networks perform inference using a weighted “network.” Weights are adjusted during the “learning” process and then applied to predict outputs from inputs.
While seemingly straightforward, the sheer number of weight parameters makes it difficult for humans to grasp their meaning.
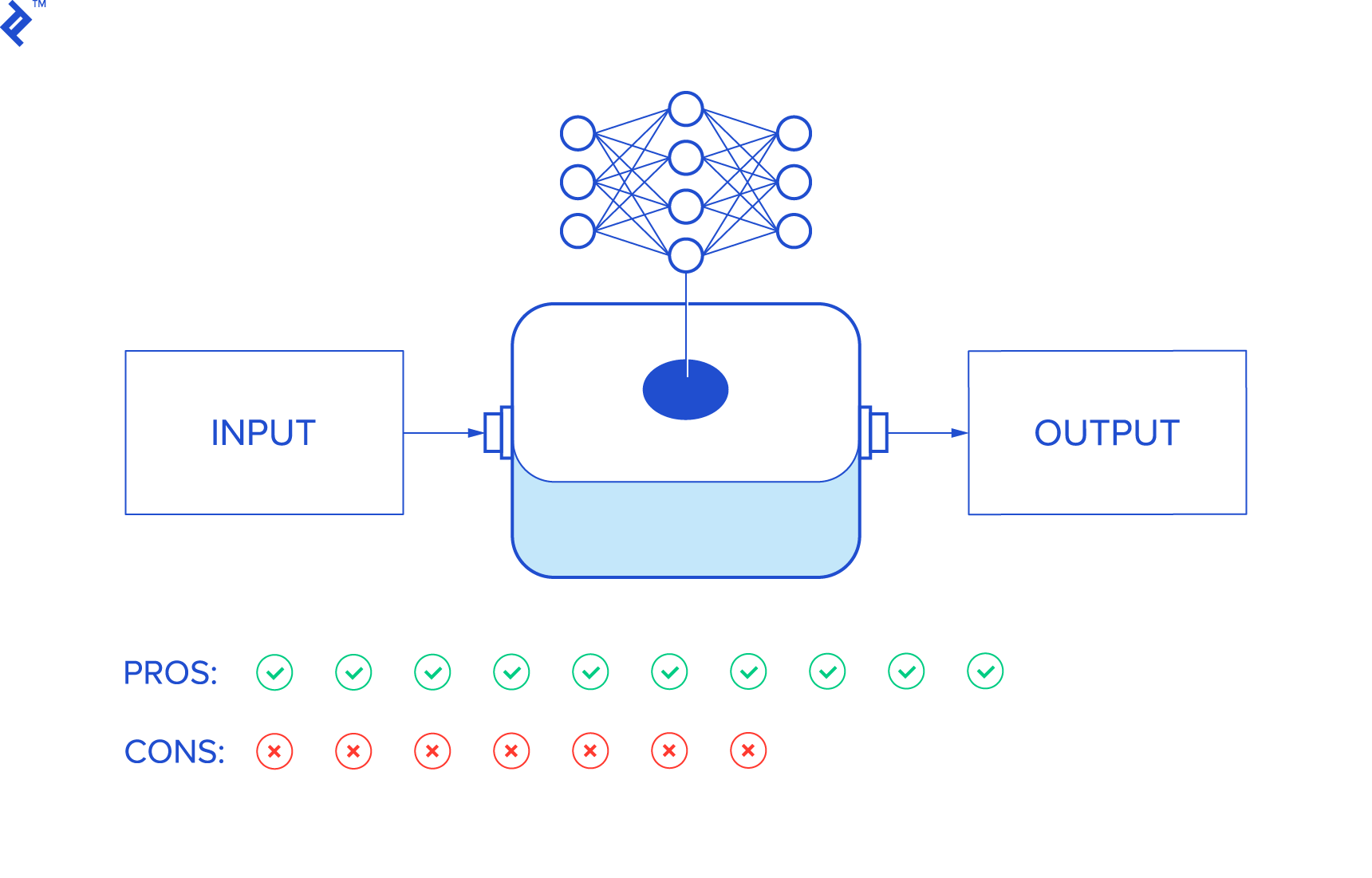
Consequently, neural networks can be considered as “black boxes” connecting input to output without a clear model in between.
Let’s examine the advantages and disadvantages of this approach.
Advantages of Neural Networks
- Data-driven input: Usable results with minimal or no feature engineering.
- Trainable expertise: No need for hard-to-find domain expertise or intuition with no feature engineering. Generic tools can be used for inference.
- Improved accuracy with data: Performance improves with increasing data inputs.
- Potential to outperform traditional models: Especially when incomplete model information exists, such as in sentiment analysis.
- Open-ended inference for pattern discovery: Unlike models with predefined considerations, neural networks can uncover unknown patterns.
Successful neural network example: Google’s detection of AI found a planet around a distant star using telescope data—a feat NASA missed.
Disadvantages of Neural Networks
- Data-intensive: Requires substantial annotated data, which is often unavailable. Slow convergence compared to models that can be calibrated with fewer observations. Annotation is labor-intensive and prone to errors.
- Lack of data structure insights: Provides no information about the underlying data structure. In cases where manual data adjustments significantly improve inference, neural networks offer no help.
- Overfitting: Networks with more parameters than data supports can lead to suboptimal inference.
- Performance reliance on information: With complete problem information, well-defined models often outperform neural networks.
- Sampling challenges: Neural networks are sensitive to biased data and learn only from the provided data, leading to biased conclusions.
Example of failure: A major corporation (unnamed) aimed to detect military vehicles in aerial images. However, the system learned to differentiate between sunny and rainy days due to the biased dataset, where most vehicle images were taken on rainy days.
In essence, neural networks are one type of inference method with inherent advantages and disadvantages.
Their widespread popularity over other statistical methods is likely driven by corporate factors rather than purely technical superiority.
Training personnel to utilize standardized tools and neural network methods is more predictable than seeking domain experts from diverse fields. However, using a neural network for a straightforward, well-defined problem might be excessive. It demands substantial data and annotation effort, potentially underperforming compared to a robust model.
Nevertheless, their ability to “democratize” statistical knowledge is significant. Viewing neural network-based solutions as programming tools empowers individuals who might not be comfortable with complex algorithms. Consequently, many applications that wouldn’t exist without neural networks are being developed.
Approaching Machine Learning Problems
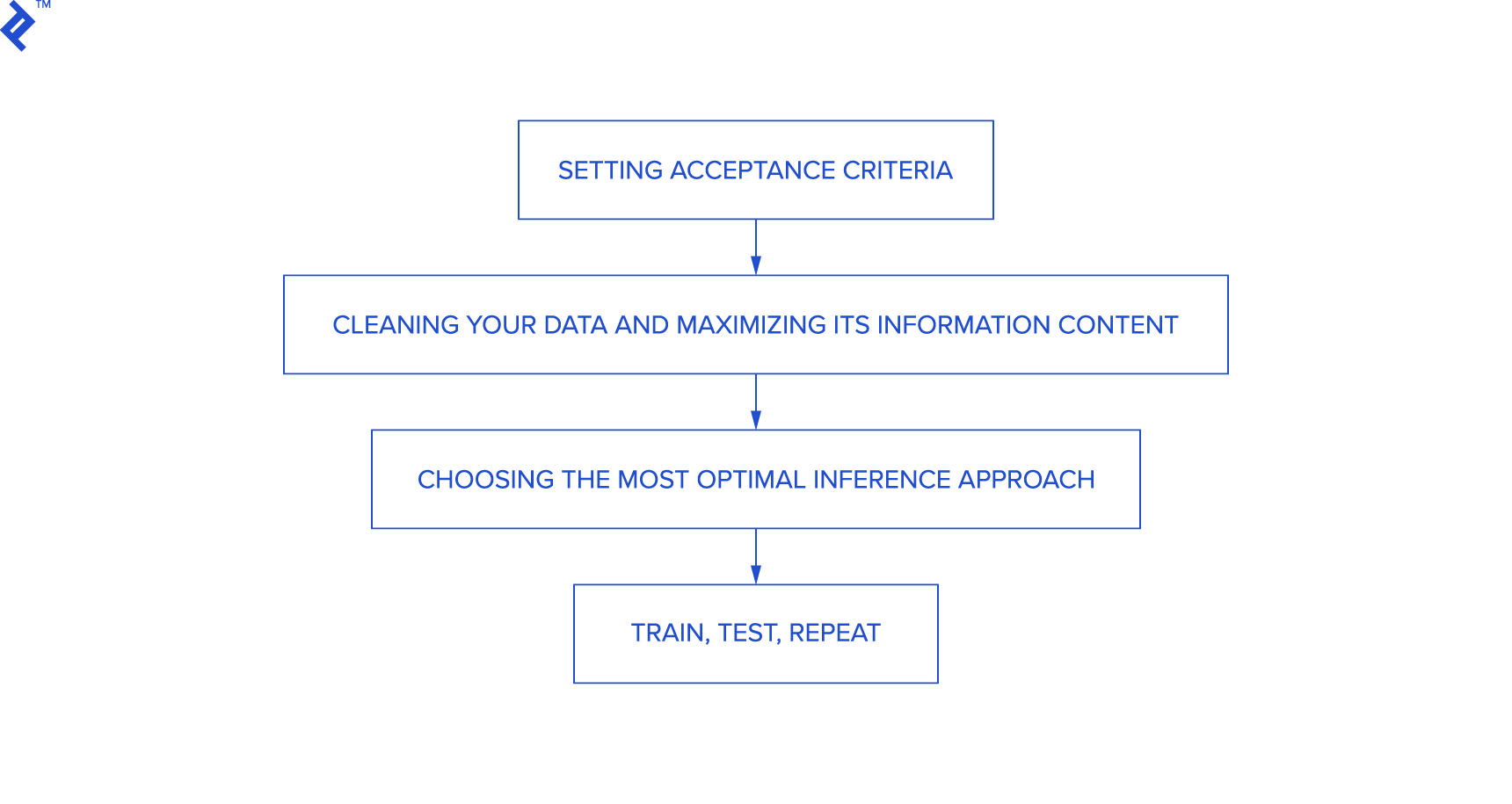
Consider these steps when addressing machine learning problems:
- Define acceptance criteria
- Cleanse and maximize data information content
- Choose the optimal inference approach
- Train, test, and iterate
Let’s explore these steps in detail.
Setting Acceptance Criteria
Establish a target accuracy level early on. This will guide your efforts.
Cleansing Your Data and Maximizing Its Information Content
This crucial step involves ensuring data accuracy and maximizing its usefulness. Begin by eliminating errors: substitute missing values, identify and address inconsistencies, remove duplicates, and address any anomalies.
Data informativeness is key. Highly informative data (in the linear sense) leads to good results regardless of the inference method. If crucial information is missing, the output will be unreliable. Maximizing information involves finding and linearizing non-linear relationships within the data. Adding more variables might be necessary if this doesn’t yield significant improvement. Target accuracy might be impacted if these efforts are unsuccessful.
Identify useful individual variables by plotting them against target variables. A function-like plot (narrow input range corresponds to a narrow output range) indicates usefulness. Linearize such variables, for example, by subtracting values and taking the square root for a parabolic plot.
Combine noisy variables (narrow input range maps to a wide output range) with others to improve their usefulness.
Assess accuracy by measuring conditional class probabilities for each variable (classification problems) or using simple regression techniques like linear regression (prediction problems). Improved input information translates to better inference. Keep testing simple at this stage, as you don’t want to waste time calibrating a model with insufficient data.
Choosing the Most Optimal Inference Approach
With your data refined, you can select an inference method (further data refinements may occur later).
Model or no model? If a suitable model can be built for the task, go for it. If not, but ample annotated data is available, consider a neural network. However, practical applications often lack sufficient data for this.
Balancing accuracy and coverage can be highly effective. Hybrid approaches are viable. Imagine achieving near-perfect accuracy on 80% of the data using a simple model. This demonstrates quick results. If your system can identify this “friendly” territory, you’ve addressed a significant portion of the problem, building trust with your client. Now, focus on the remaining data: with reasonable effort, achieve, say, 97% accuracy on 92% of the data. While the rest might be a toss-up, you’ve already delivered value.
This approach is practical in various scenarios. For instance, in lending, if your algorithm boasts high accuracy for 70% of loan applicants, you’ve automated a significant portion, even if the remaining 30% require further scrutiny. Similarly, in call center automation, efficiently handling even the simplest 50% of calls translates to cost savings.
In conclusion: Think outside the box if the data lacks information or the problem is overly complex. Break it down into manageable sub-problems until you gain a clearer understanding.
Once your system is ready, proceed to learning, testing, and iterating until the desired outcome is achieved.
Train, Test, Repeat
With the data and machine learning method in place, it’s time to determine parameters through learning and evaluate the inference using the test set. A common practice is using 70% of the data for training and 30% for testing.
If the results meet your criteria, the task is complete. However, you’ll likely uncover new insights during the process, prompting further improvements. Perhaps more data, additional data cleansing, or a different model is needed. This iterative process might keep you occupied for a while.
Best of luck, and enjoy the journey!